Language Models Recognize Dropout and Gaussian Noise Applied to Their Activations
Damiano Fornasiere*, Mirko Bronzi*, Spencer Kitts*, Alessandro Palmas, Yoshua Bengio†, Oliver Richardson†
We provide evidence that language models can detect, localize and, to a certain degree, verbalize the difference between perturbations applied to their activations. More precisely, we either (a) mask activations, simulating dropout, or (b) add Gaussian noise to them, at a target sentence. We then ask a multiple-choice question such as “Which of the previous sentences was perturbed?” or “Which of the two perturbations was applied?”. We test models from the Llama, Olmo, and Qwen families, with sizes between 8B and 32B, all of which can easily detect and localize the perturbations, often with perfect accuracy. These models can also learn, when taught in context, to distinguish between dropout and Gaussian noise. Notably, Qwen3-32B’s zero-shot accuracy in identifying which perturbation was applied improves as a function of the perturbation strength and, moreover, decreases if the in-context labels are flipped, suggesting a prior for the correct ones—even modulo controls. Because dropout has been used as a training-regularization technique, while Gaussian noise is sometimes added during inference, we discuss the possibility of a data-agnostic “training awareness” signal and the implications for AI safety.1
1. Introduction
A common recipe for robustness, be it to distribution shifts, overfitting, or training instability, is to “add randomness”. This prescription is under-specified and yet, in the context of language models, it does conjure a mental image: activations jittered by a small amount. Provided a perturbation is not biased in any particular direction (unlike, for instance, steering vectors) and its magnitude (e.g., entropy or variance) is specified, other aspects of the distribution may seem to be higher-order concerns that can be neglected.
Yet, not all such interventions are alike, and indeed they are employed in different contexts. Some, such as dropout [Hinton et al., 2012, Zehui et al., 2019], are used to regularize training, while others, such as additive Gaussian noise, are used during inference [Tice et al., 2025, Liu et al., 2025b]. Might a language model be able to distinguish between the two?
Recent work suggests that language models can detect and verbalize steering vectors applied to their activations [Lindsey, 2025, Pearson-Vogel et al., 2026a], a phenomenon the authors call introspection. Whether these results show retrodictive recognition of the injected concepts is debated [Comsa and Shanahan, 2025, Hahami et al., 2025, Lederman and Mahowald, 2026]. Even granted that, steering vectors themselves may bias the model toward the answer being probed.
In this work we revisit this question in a setting without semantic steering. In particular, we test open-weight models from the Llama, Olmo, and Qwen families for the ability to locate, recognize, and learn (in-context) the difference between dropout and additive Gaussian noise. We do so by perturbing the activations corresponding to the tokens of a target sentence in a prompt, and then posing binary-choice questions, as illustrated in Figure 1.
*Equivalent contribution.
†Supervision
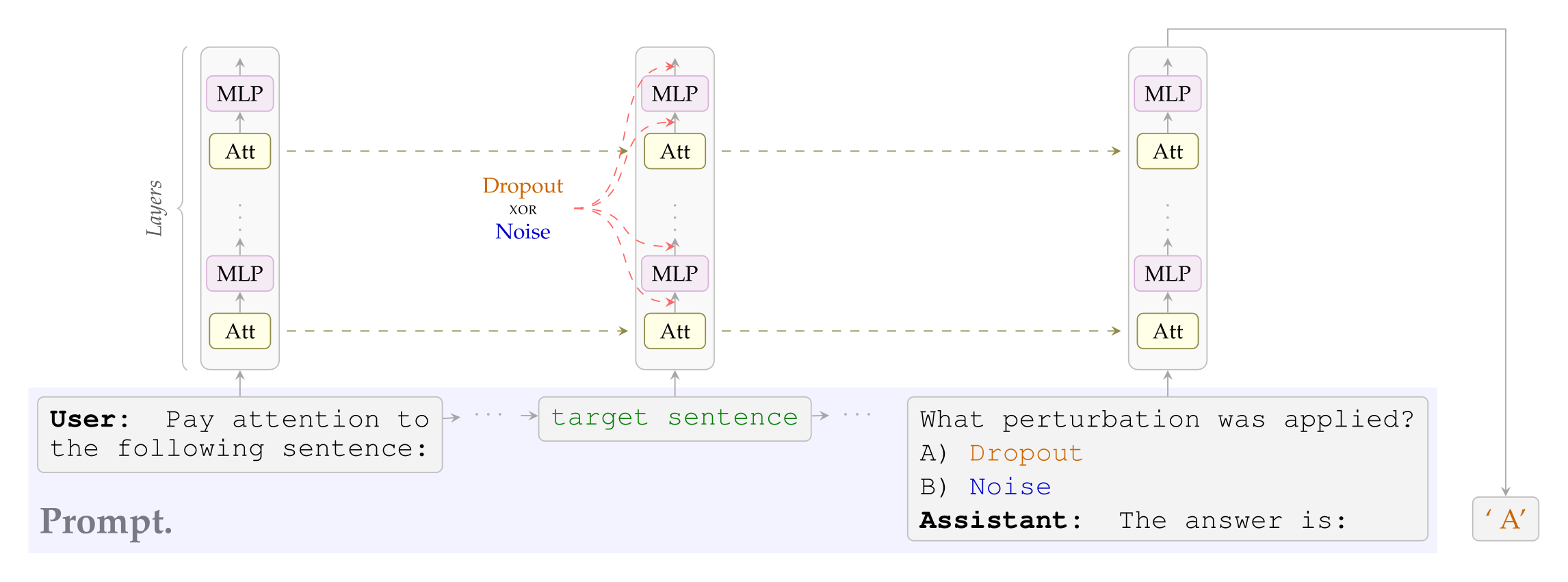
Figure 1: We perturb the activations of a target sentence by either masking activations or adding Gaussian noise. In the same prompt we then ask the model to identify which perturbation was applied. Success is measured as accuracy of the most-likely next-token.
We report that:
(i) All the models we tested can easily detect and localize the injected perturbation with at least an 80% accuracy, with the Qwen models reaching a perfect score (§4.1). We establish by control that this is not because the perturbation pushes the model to disproportionally choose the perturbed sentence (§4.2).
(ii) The zero-shot accuracy for (just) one model, Qwen3-32B, monotonically increases with the perturbation strengths (§5.1). This behavior holds even with synonyms of dropout and noise such as ‘masking’ and ‘jitter’, but is not visible with control labels (such as ‘rotation/permutation’, ‘X/Y’, ‘vanilla/chocolate’, etc.).
(iii) Models can learn, when supervised with in-context labels, to distinguish dropout from Gaussian noise. In particular, the accuracy of both the 14B and 32B Qwen3 models increases with as few as one or two examples (§6.1). Furthermore, the accuracy of Qwen3-32B drops when the in-context labels are swapped (even modulo controls; §6.2), again suggesting a prior for the correct labels.
In light of recent interest in evaluation awareness (see, e.g., Bengio et al. [2026, pp. 10, 76], which lists it among the key developments of the past year), we observe that “training awareness” may present a similar problem. Our results suggest that some models have a prompt-independent sense for the difference between dropout, a perturbation often deployed during training, and Gaussian noise, which has seen more use during inference. It is striking that we see such an effect at all, because the models we test have not, according to their technical manuals, undergone either perturbation during training. Fortunately, unlike the fundamental distribution shift that makes evaluation awareness difficult to handle, this signal is relatively easy to remove in practice—and this tractability makes understanding the phenomenon especially important.
2. Prior work
Dropout and Gaussian noise. Dropout is a classic training-time regularization technique [Hinton et al., 2012] that has been been applied in transformers too [Vaswani et al., 2017, Zehui et al., 2019, Li et al., 2023]. Nonetheless, there is no universal agreement about the optimal dropout strategy with language models, with some work removing even entire layers [Fan et al., 2019] or attention heads [Zhou et al., 2020]. Recent language models rely less on dropout, with many omitting it altogether [Almazrouei et al., 2023, Liu et al., 2025a], although some still employ variants of it [Elhoushi et al., 2024]. Adding Gaussian noise to a model’s activations has also been used as a regularizer—see, e.g., Camuto et al. [2020]. Beyond regularization, Tice et al. [2025] tests adding Gaussian noise into a model’s weights in a safety context, so as to yield anomalous improvements in performance with the goal of detecting “strategic under-performance”.
Concept vectors and introspection. Adding steering vectors into the activations of language models is a standard interpretability technique—see, e.g., Turner et al. [2023], Zou et al. [2023], Panickssery et al. [2024]. Recent work suggests that language models can sometimes correctly answer questions about the steering itself: for instance, Lindsey [2025] reports that Claude Opus 4.1 can identify the steering direction, and Pearson- Vogel et al. [2026b] extends these findings to the open-weight model Qwen2.5-Coder-32B-Instruct. The extent to which this can be attributed to “introspection” is under discussion [Comsa and Shanahan, 2025, Lederman and Mahowald, 2026]—and investigating these questions is made harder by the fact that steering along semantically-meaningful directions may bias models toward the answer under probation.
3. Methodology
We assume familiarity with the terminology of autoregressive language models based on the decoder-only transformer architecture. Fix a vocabulary of tokens V and a language model M. In our experiments M is either Llama3.1-8b, Olmo3.1-32b, Qwen3-14b, or Qwen3-32b.2
Where \( X \) is a set, \(X^{*}\)denotes the set of finite strings over it. A prompt is a nonempty string \( x\in V^{*}\) and, in our setup, it always represents a binary-choice question with exactly one correct answer \(v^{*}\in V \) . The model M decodes the entirety of x and in so doing it induces, through the output of the unembedding matrix, a logit vector \( l \in R^{V} \) over tokens. In particular, \( l(v) \) is the logit associated with a token \( v \in V \) given \( x \), while the corresponding conditional probability is \( p(v):=softmaxV(l(v)) \). In the interest of reproducibility and compute efficiency, we do not allow \( M \) to generate. Therefore, we interpret \( \hat{v} := \arg\max_{v \in V} l(v) \) as \(M\)’s answer to \( x \).
Prompts. Our goal is to measure \(M\)’s performance on an introspective prompt, i.e.., a prompt \(x\) that is about \(M\)’s activations when decoding \(x\) itself. All prompts employ a chat-template prompt with pre-filled answers, and take a similar form—see Figure 1 for an example and Appendix A.2 for the exact prompts. In particular, each prompt contains one or more target sentences whose activations may be perturbed during the decoding. The number of perturbed sentences, the selection of which perturbations to apply, and the question posed to the model, all vary among experiments. Nonetheless, every experiment uses 20 prompt variants and, to further increase prompt diversity, the target sentences are sampled from a pool of \( 1.2 \times 10^{4} \) sentences extracted from WikiText-103 [Merity et al., 2016].3
Perturbing activations with dropout and Gaussian noise. For each token of the target sentence and each layer of \(M\), we use forward hooks to modify the corresponding Attention and MLP output vectors by either: (i) applying dropout4, i.e., zeroing out each entry of the vector independently with dropout rate \( p \in \) [0, 1), then rescaling all the entries by \( 1/1 - p \); or (ii) adding Gaussian noise with mean 0 and standard deviation (SD) \(σ\). See Figure 1.
3.1 Metrics
All our experiments consist of a binary classification task with \( n \geqslant 1000 \) samples. Success is measured as accuracy a of the most-likely next token: the fraction of the time that \(M\) answers correctly, i.e., \( \hat{v} = v^{*} \). Since \(a\) is the mean of \(n\) i.i.d. Bernoulli trials its standard error is \( SE = \sqrt{a(1-a)/n} \). The theoretical maximum of \(SE\) is approximately 1.581% when \( a = \frac{1}{2} \).
Multiple correct answers. The correct answer need not correspond to a single token. For example, M may distribute the probability mass across casing variants of the same label, such as with or without a leading space. Accordingly, we define correctness up to these variants and compute accuracy over the corresponding enlarged answer space. Empirically, this aggregate accuracy is identical to the baseline accuracy, so we report only the latter.
4. Localization
Our first first experiments test whether language models can localize, and hence detect, a perturbation, by selecting one sentence among two. To this aim, we follow the experimental design described in Section 3.

We present \(M\) with two target sentences, only one of which will be perturbed. We then ask \(M\) which of the two sentences was perturbed. We run two batches of parallel experiments: one where the perturbation is always dropout (at different dropout rates \(p\)), one where the perturbation is always noise (at different standard deviations \(σ\)). The prompt is the same in both experiments, so as not to bias the model by using the words “dropout” or “noise”. Moreover, using a unique prompt will help to find comparable scales of \(p\) and \(σ\) (cf. §4.2).
4.1 - Results
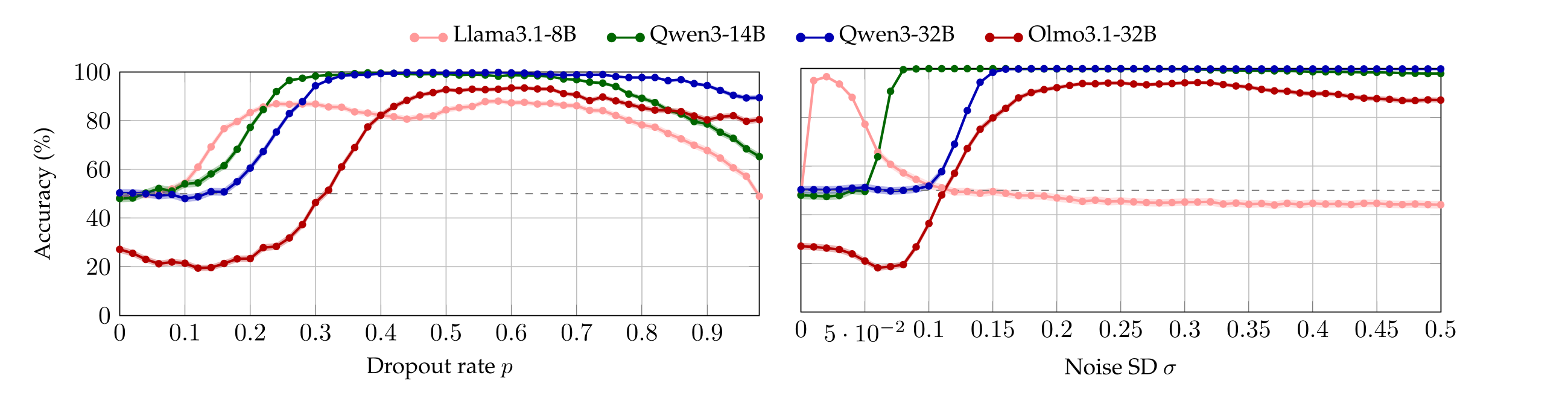
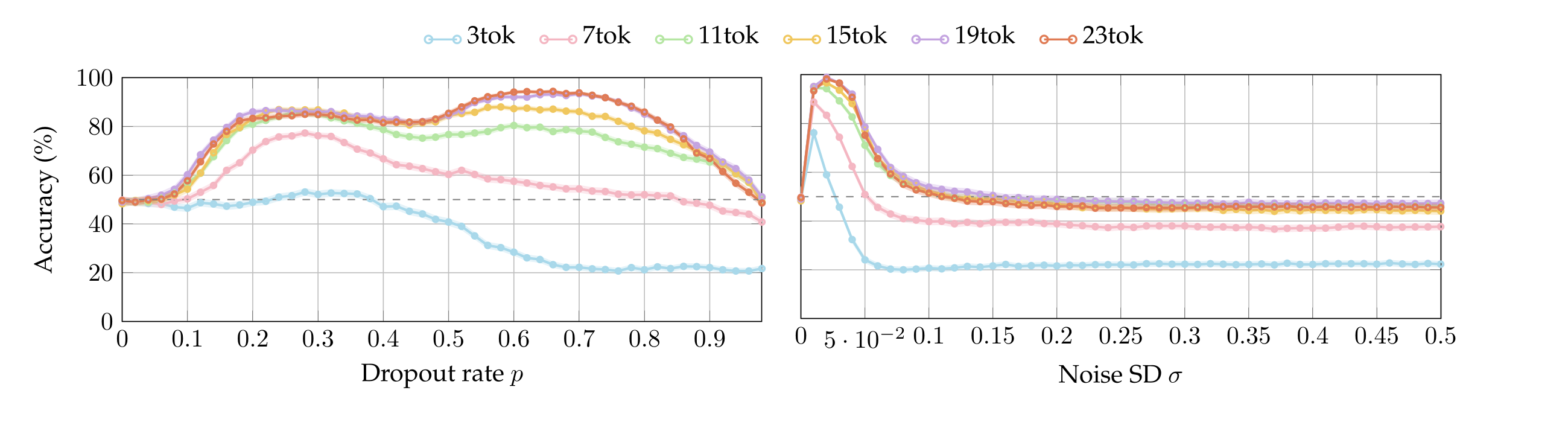
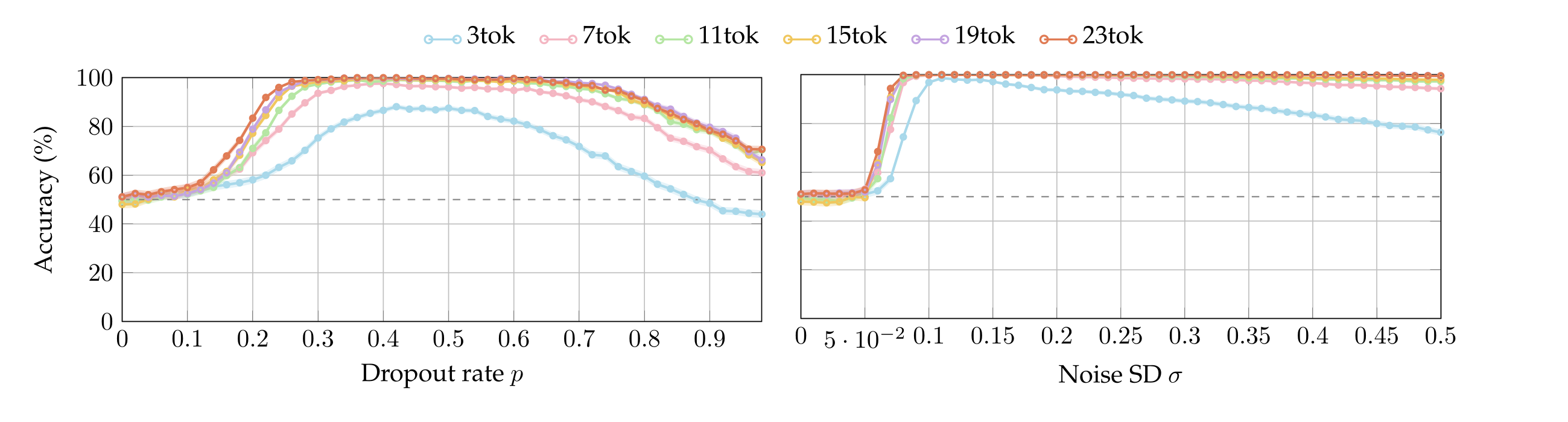
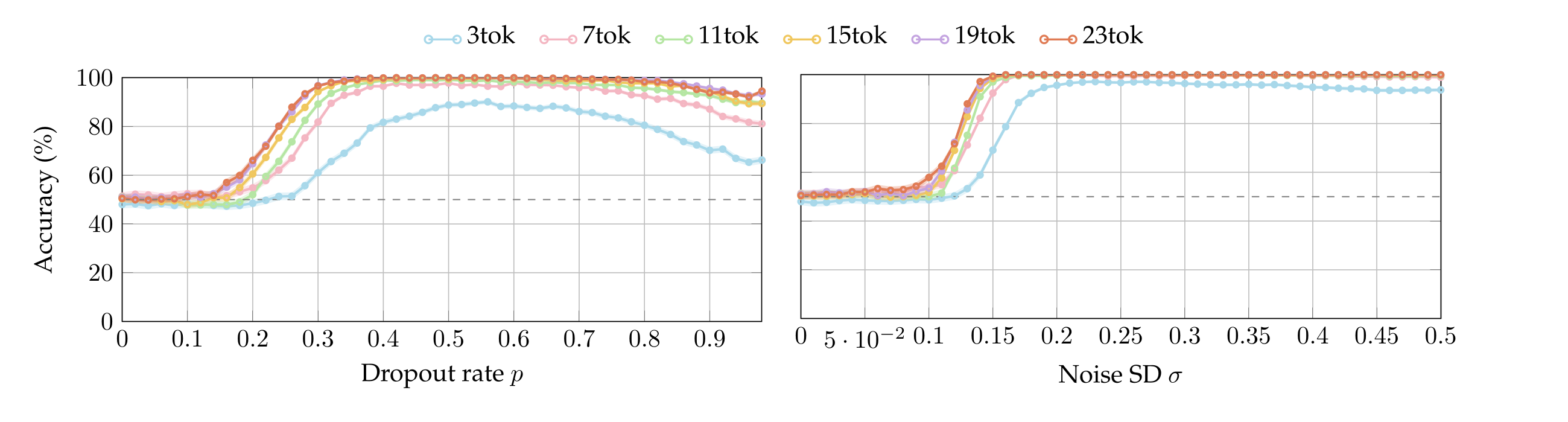
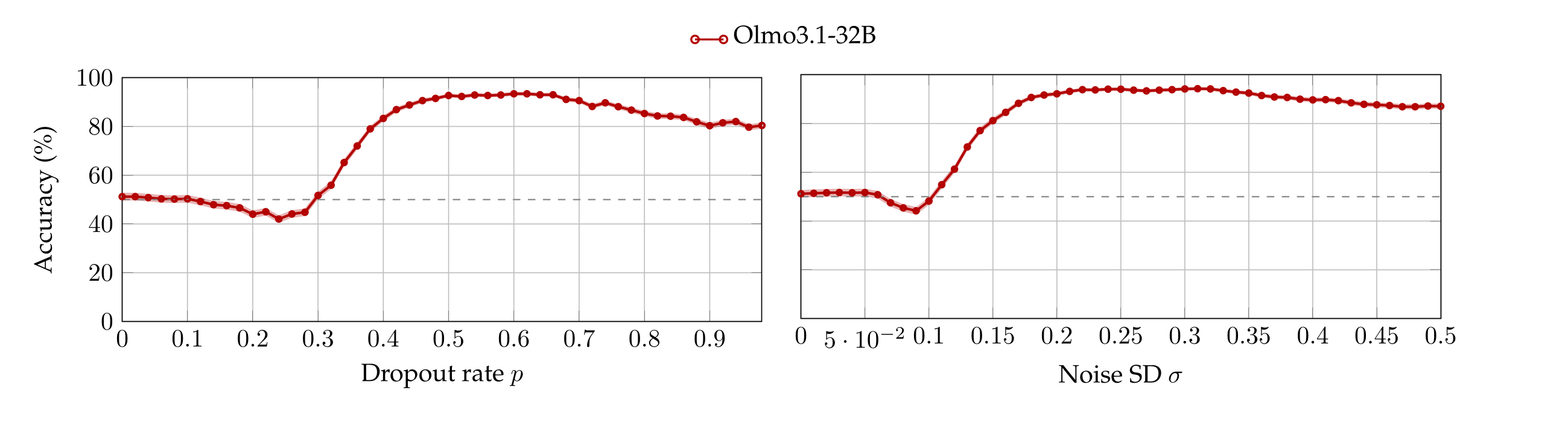
We run the same batches of experiments by varying the number of tokens in the target sentences between 3 and 23 (cf. Appendix §A.4). We observe that the accuracy-plots look alike after 15 tokens, so here we report only that (nonetheless, most models achieve up to 90% accuracy even when the perturbed sentence has only 3 tokens, see Appendix A.4). Figure 2 plots the accuracy of each model as a function of p and σ. Observe that in contrast with the chance-level accuracy when neither dropout or noise are applied (\(p = σ = 0\)), all models are capable to localize both perturbations with accuracy around or above 80% as soon as \(p\) or \(σ\) are high enough—notably, the Qwen models achieve perfect accuracy. We highlight that Llama3.1-8B is sensible to extremely small values of noise. Interestingly, Olmo3.1-32B starts below chance because, at low perturbation magnitudes, it answers “neither”.
Perturbations lower bounds. Notice that each model \(M\) admits a first value of \(p\) (resp. \(σ\)) whose associated accuracy is not 50%. We refer to this value as \( p_{\min} \) (resp. \( \sigma_{\min} \)) because, in the context of our experiment, lower perturbation strengths do not affect the model.5
4.2. Controls

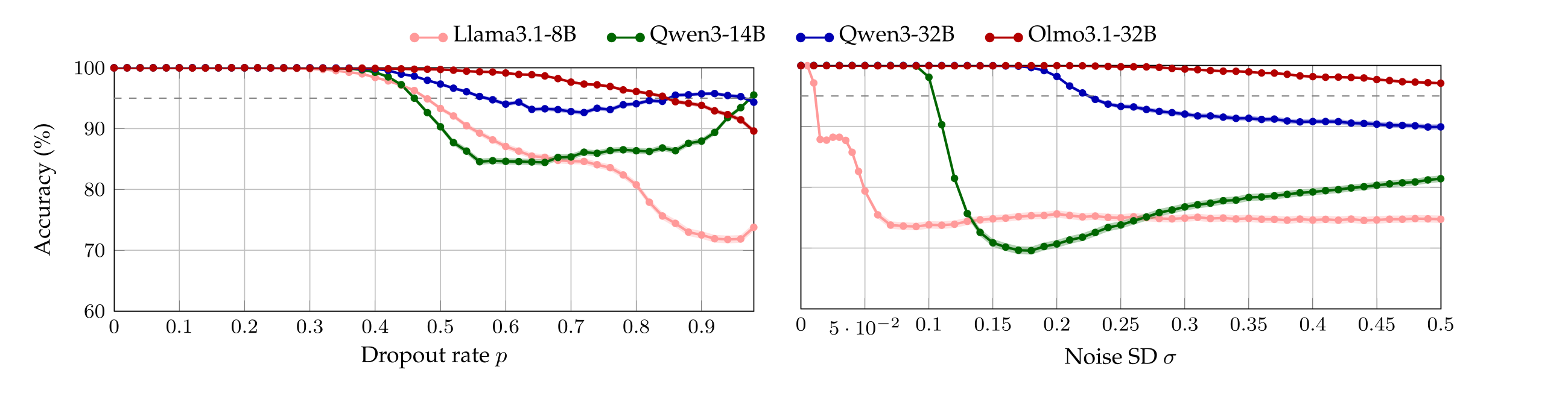
A null hypothesis that might a priori explain the results of §4.1 is that applying dropout (resp. noise) steers a model \(M\)’s activations in such a way that it disproportionally picks a perturbed sentence no matter the question \(x\). To eliminate this possibility, we run the same experiment with five sets of control prompts. More precisely, we repeat the localization experiment by presenting the model with two sentences, each exclusively about one topic. There are 5 pairs of topics, and each sentence in a pair is sampled at uniform from a pool of cardinality 40. As before, the chat-template is sampled uniformly from a pool of cardinality 20. We perturb exactly one of the sentences and ask the model a simple comprehension question (details in Appendix A.6). Figure 3 reports accuracy of every model averaged across all the control questions.
Perturbation upper bounds. In the controls all the models first display perfect accuracy, as expected for such simple questions. Yet, performance decreases as the perturbations become too salient. In particular, every model admits a first value \( p_{\max} \) of dropout rate (resp. a first value \( \sigma_{\max} \) of noise SD) whose associated accuracy drops below 95%.6 . We define these values to be the thresholds after which the models accuracies are compromised.
Conclusions from controls. Table 1 summarizes the bounds of the perturbation strengths established in §4.1 and §4.2. Observe that \( p_{\min} < p_{\max} \) and \( \sigma_{\min} < \sigma_{\max} \) always. This allows us to conclude that there exists an interval of dropout values (resp. noise values) for which we can exclude that the models localize the perturbations by disproportionally picking the perturbed sentence, irrespective of the question.
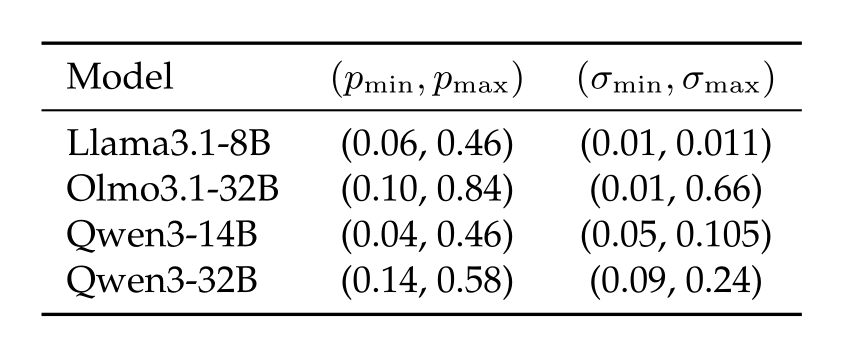
For example, Qwen3-32B and Qwen3-14B, who reach 100% perturbation detection accuracy, under the null hypothesis would achieve 50% accuracy in the control setting since, in expectation, the correct answer for the control coincides with the perturbed sentence in half the trials. Yet, their control accuracy stays above 95% in \( [p_{\min}, p_{\max}] \) and \( [\sigma_{\min}, \sigma_{\max}] \), ruling this out.
Perturbation ranges. In summary, the intervals \( [p_{\min}, p_{\max}] \) and \( [\sigma_{\min}, \sigma_{\max}] \) represent the values of \(p\) and \(σ\) where models detect perturbations yet retain their ability to answer basic questions. We divide them in 10 percentile bins each (so 11 perturbation magnitudes) and, from now on, we perform experiments only within these ranges.
5. Zero-shot classification
The previous experiment shows that the models we tested can easily detect and localize a perturbation applied to their activations. In this experiment, we test for the much harder task of classifying which perturbation was applied. To test this, we now show \(M\) only one sentence, randomly perturbed with exactly one between dropout and noise, and then ask the model which perturbation was applied.

To exclude biases towards disproportionally answering 'A' or 'B ' we randomize the assignment between letters (e.g., 'A') and perturbations (e.g., Dropout). We also randomize the order in which the perturbations names are presented in the prompt. Finally, we run the same prompt with 50 pairs of control labels. For instance, we ask the model (paraphrasing): “Did we apply Rotation or Permutation?”, but the underlying perturbations remain exclusively dropout or noise. In these controls we then keep track of the number of times the model says Rotation (resp. Permutation) when the underlying perturbation is dropout (resp./ noise).

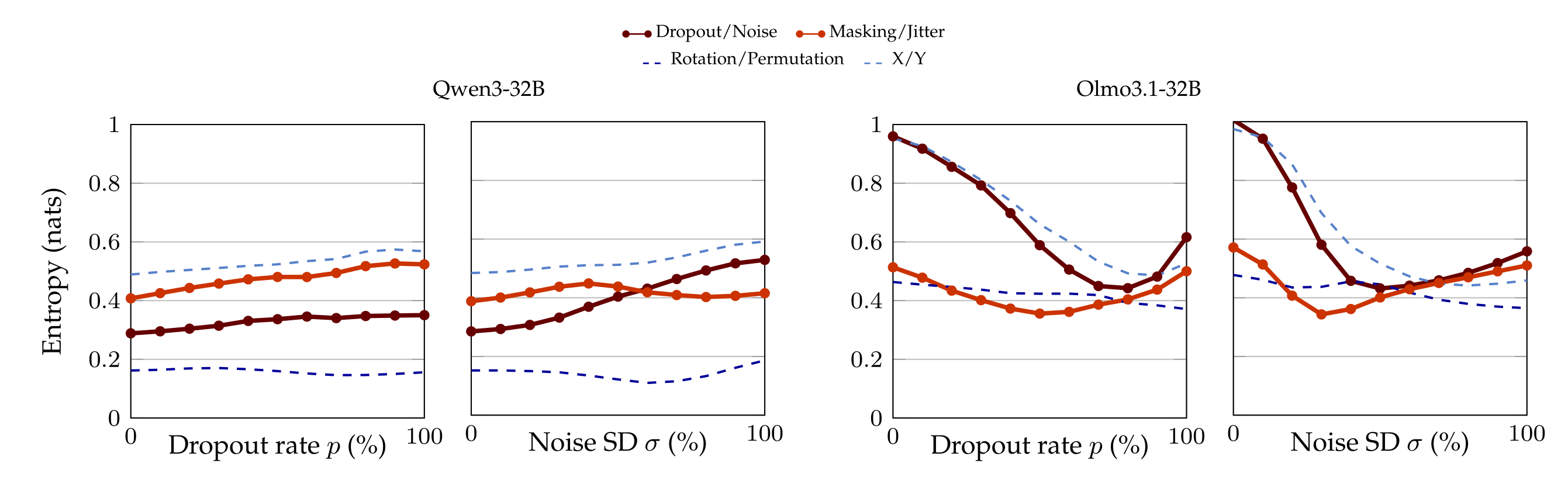
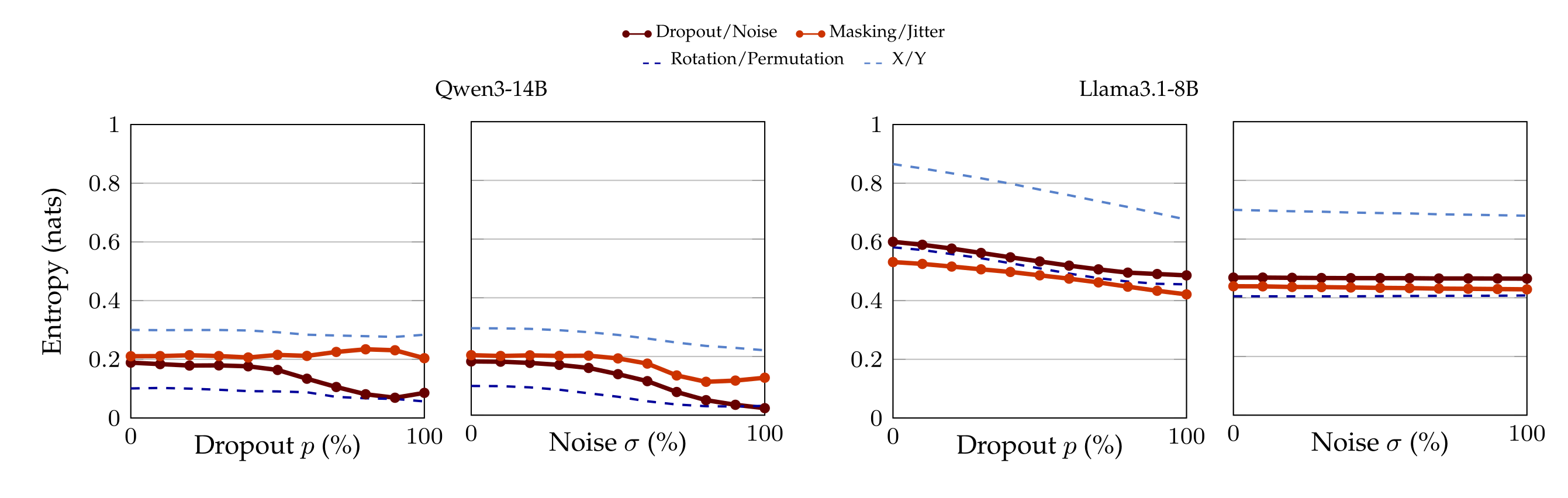
This controls for the possibility that each perturbation steers the activations in a way that systematically favors one label over another, irrespective of its semantic content. For instance, dropout might steer to choose in the same way that it steers to pick Rotation over Permutation. For this reason, we also keep track of the average entropy of the distribution of tokens (cf. Appendix A.9). Finally, most of the control labels are semantically unrelated to dropout and noise, but we also use pseudo-synonyms of dropout and noise such as Masking and Jitter (complete list in Appendix A.7).
5.1 Results
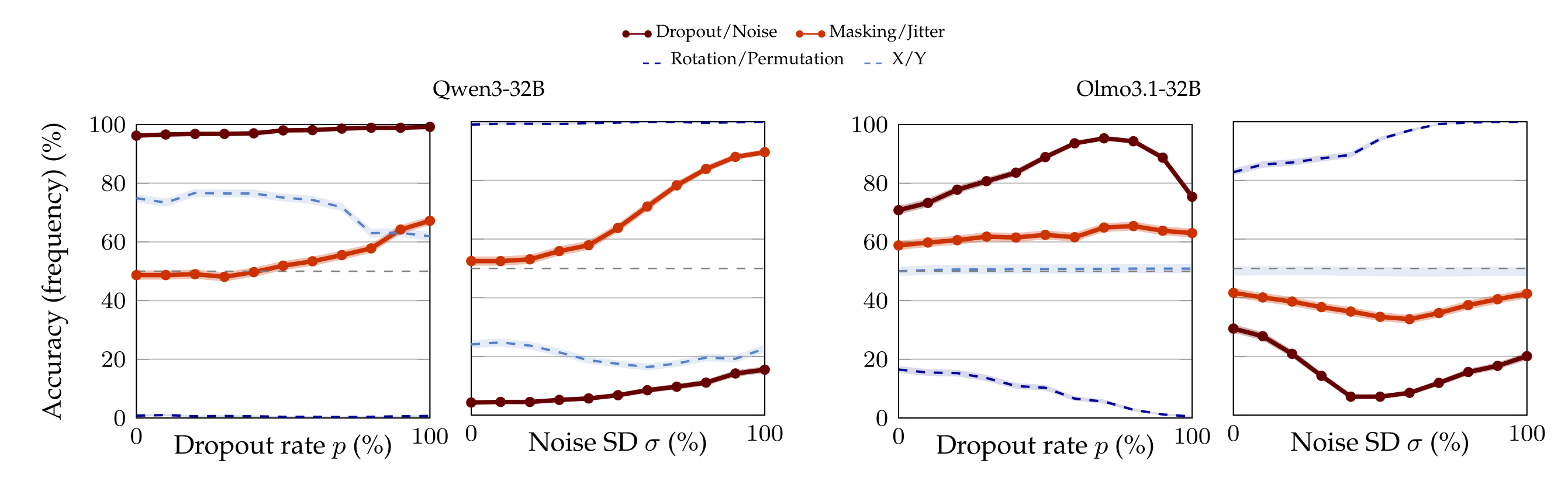
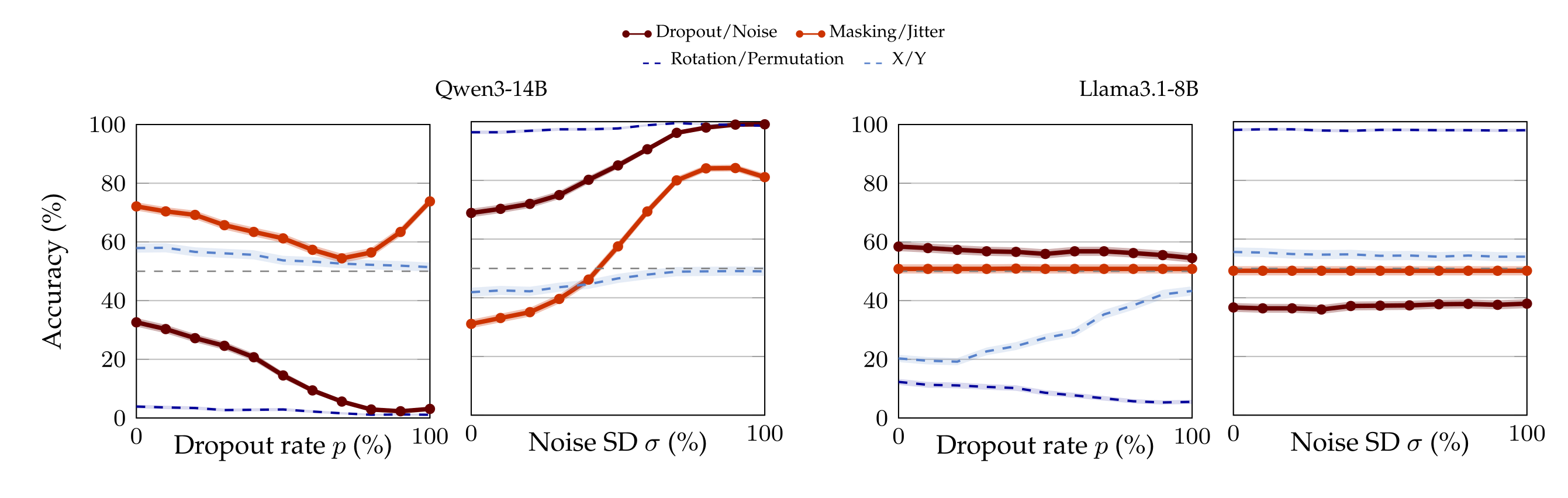
Figure 4 shows the number of times the models answer dropout (or, e.g., rotation, in the associated control) when in fact dropout is applied (first and third plot from the left), and the number of times models answer noise (or, e.g., permutation, in the associated control) when in fact noise is applied (second and fourth plot from the left). For ease of visualization and comparison, this section focuses on Qwen3-32B (the best performing model) and Olmo3.1-32B (for whom it appears there is little-to-no signal). The complete list of results can be found in Appendix A.8.
Qwen3-32B starts with a very high prior to answer dropout over noise: even at \( p_{\min} \), the model says “dropout” 96.20% of the times when dropout is applied. Still, accuracy continues to increase as dropout rate increases, reaching 99.20% at \( p_{\max} \) (first plot on the left, dark red curve). Similarly, despite the low prior to answer “noise“ (with the model saying it only 4.30% of the times when noise is injected at magnitude \( \sigma_{\max} \)), Qwen3-32B reaches 15.50% accuracy in the noise samples at σmax (second plot from the left, dark red curve).
This trend does not seem to be an artifact of the strong prior over dropout. In fact, the model has an almost 50% prior between “masking” and “jitter”, pseudo-synonyms of dropout and noise. And in this case a double rise in accuracy is even more pronounced (light red curves): for instance, when noise is applied, the model identifies the correct perturbation 89.60% of the times. This is not an isolated finding, for we observe similarly monotone trends with other aliases of dropout, noise, and their permutations.
Because Qwen3-32B is the only model that performs so well, we ran 50 control pair aliases for it (as opposed to 6 controls for the other models), and we do not observe the same phenomenon. For instance, there is no amount of dropout rate or noise SD that make the model flip its answer with the ⟨Rotation, Permutation⟩ labels (dark blue curve). Semantically-meaningless label pairs, such as ⟨X;Y⟩ (light blue curve) also do not induce a behavior similar to ⟨Dropout, Noise⟩ or their synonyms.
We may interpret this as Qwen3-32B in fact having signal to associate the perturbation with the correct semantic meaning. However, we remark that this is the only model for whom we observed this pattern (cf. Appendix A.8). For instance, observe the plots for Olmo3.1-32B in Figure 4, whose symmetric nature leave doubts as to whether the model shows any signal of understanding. This raises the questions of whether we encountered an isolated finding and, moreover, if other models can learn to distinguish dropout from noise.
6. Few-short classification
We have seen that, while at least one model can identify perturbations out-of-the-box, the capacity is far from universal. In our last series of experiments, we test if models can nevertheless learn to distinguish dropout from noise when supervised with in-context labels [Brown et al., 2020].

We do so by showing \( k \in \) {1, 3, 5, 7, 9} pairs of labels of the form ⟨dropout; noise⟩, or vice versa, and then ask a model to predict the perturbation type on a test sentence. 7 We randomize (i) the assignment between letters and perturbations, (ii) the order in which the perturbations are presented in the final question, (iii) the order of dropout and noise in each teaching pair.
6.1. Results
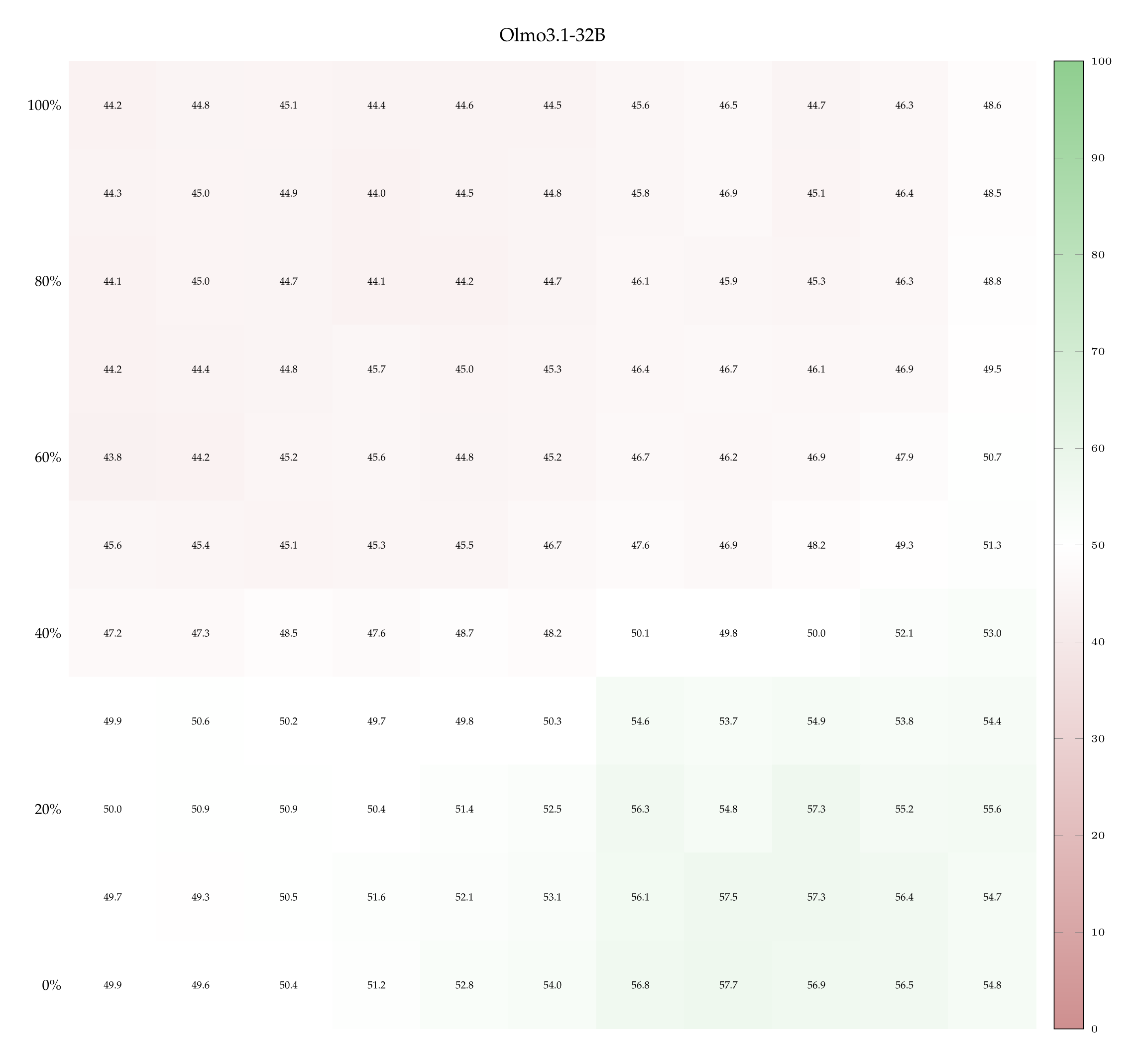
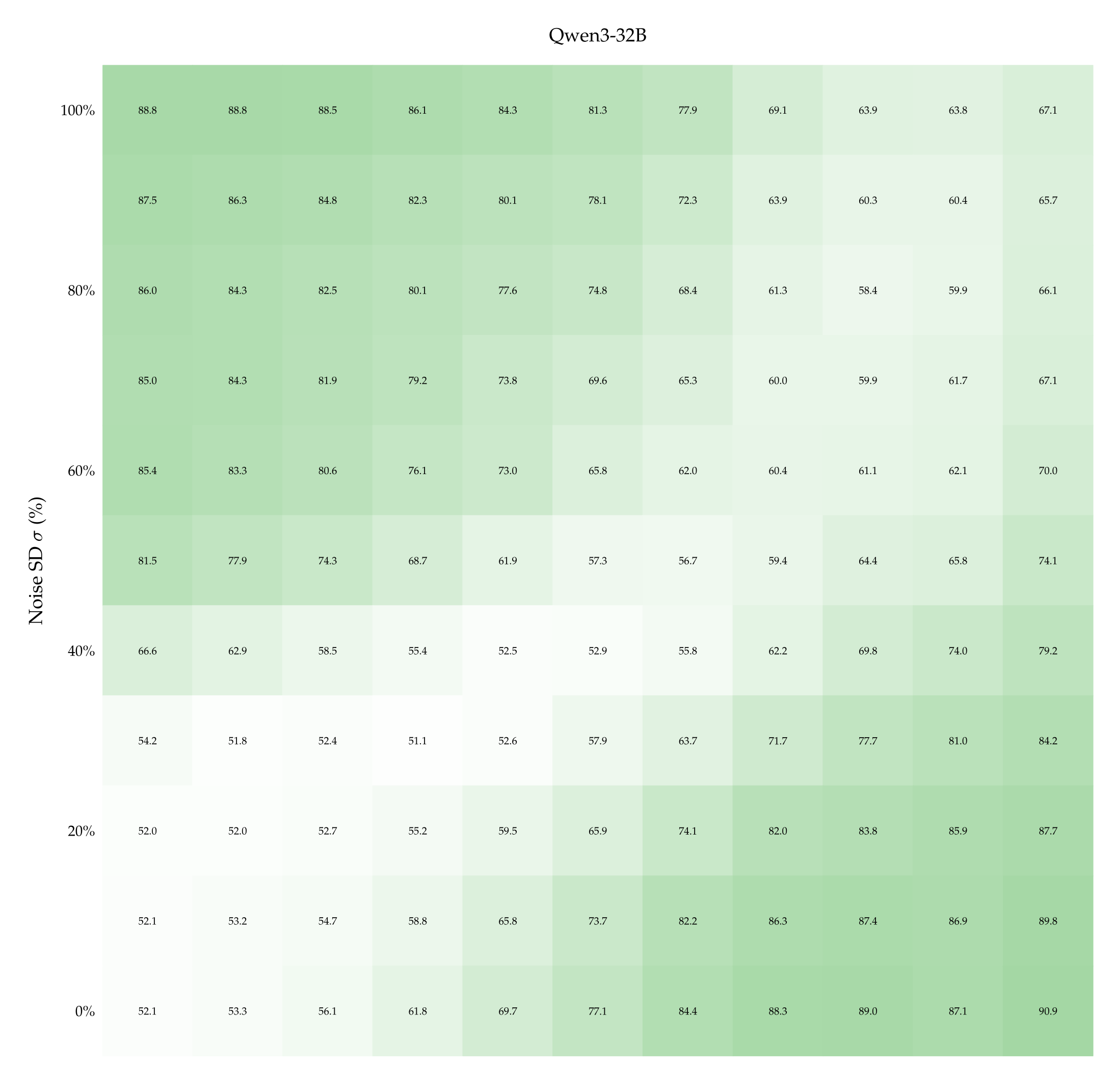
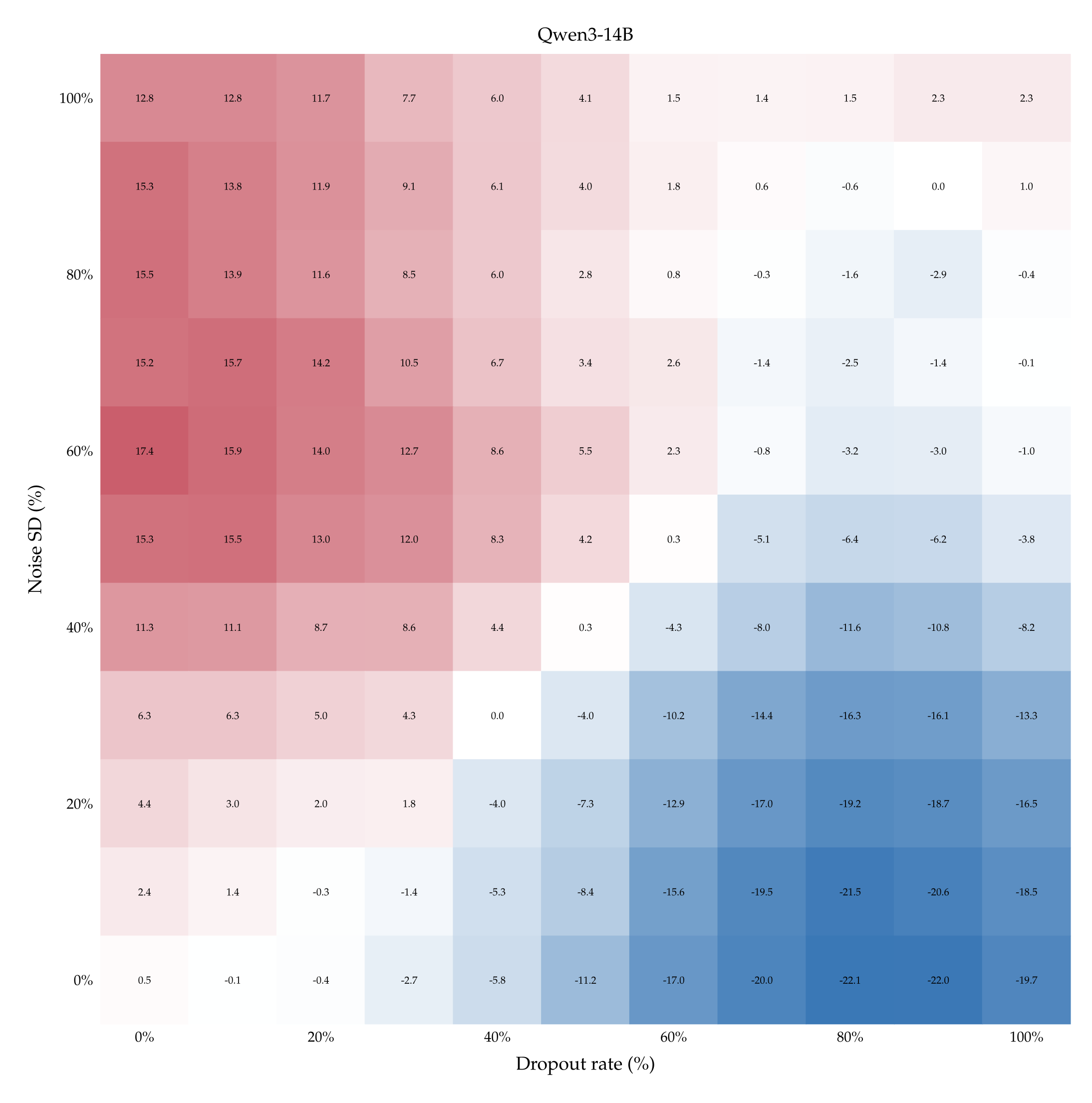
Accuracy with one teaching pair. The left-hand side of Figure 5 shows accuracy (heat) as a function of both dropout rate \(p\) and noise SD \(σ\) when Qwen3-32B is supervised with \(k = 1\) labeled pair (see Appendix A.10 for the heatmaps associated with the other models and more teaching examples). The ranges of \(p\) and \(σ\) are the ones we computed previously (cf. Table 1). Observe that accuracy improves if dropout rate increases while noise SD remains fixed (bottom-right quadrant), and vice versa (top-left quadrant). Accuracy also rises when both perturbations increase in strength along each other: compare the almost-chance accuracy when both \(p\) and \(σ\) are low (bottom-left quadrant) with the \( \geqslant \) 60% accuracy when both \(p\) and \(σ\) are high (top-right quadrant).
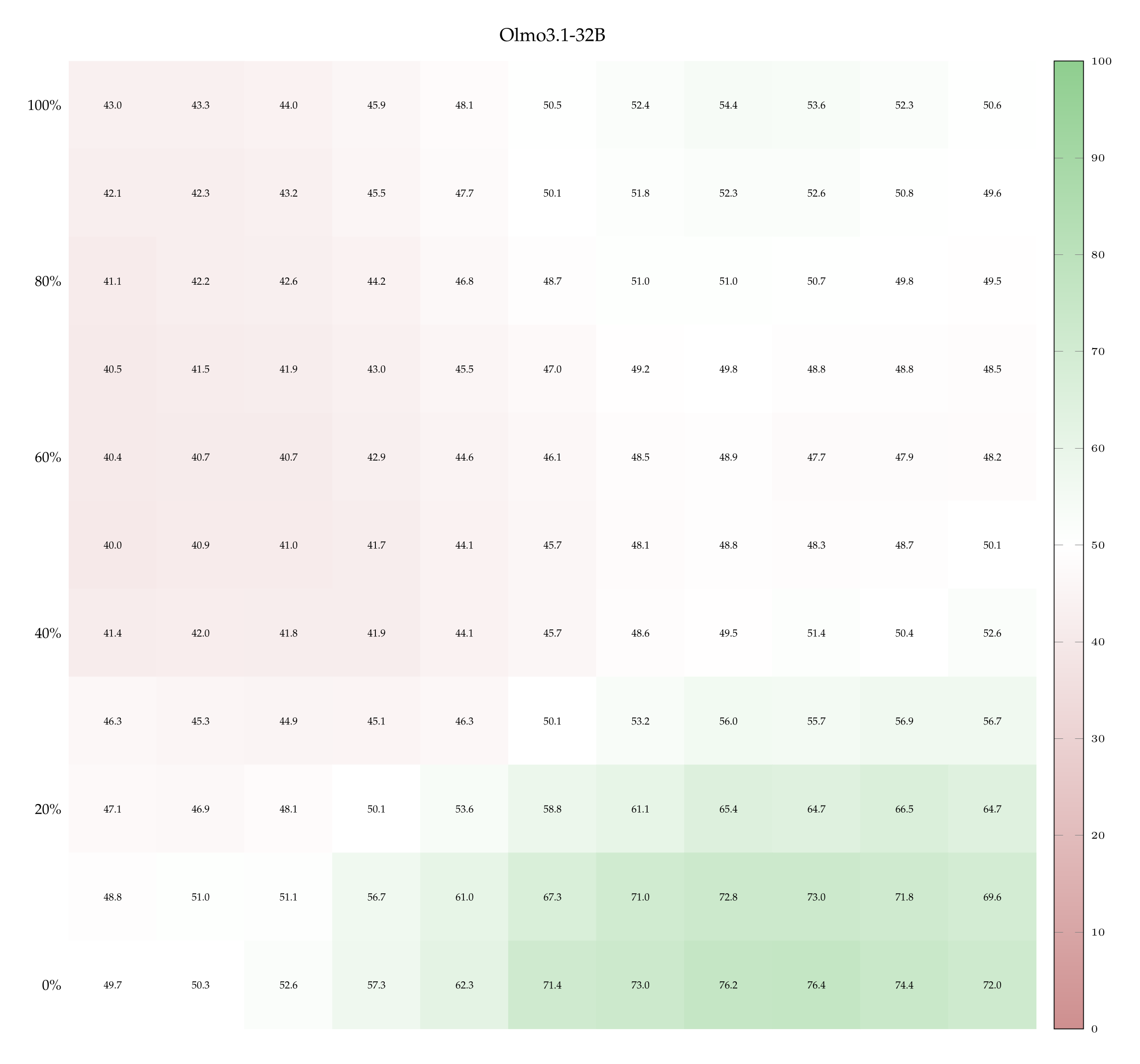
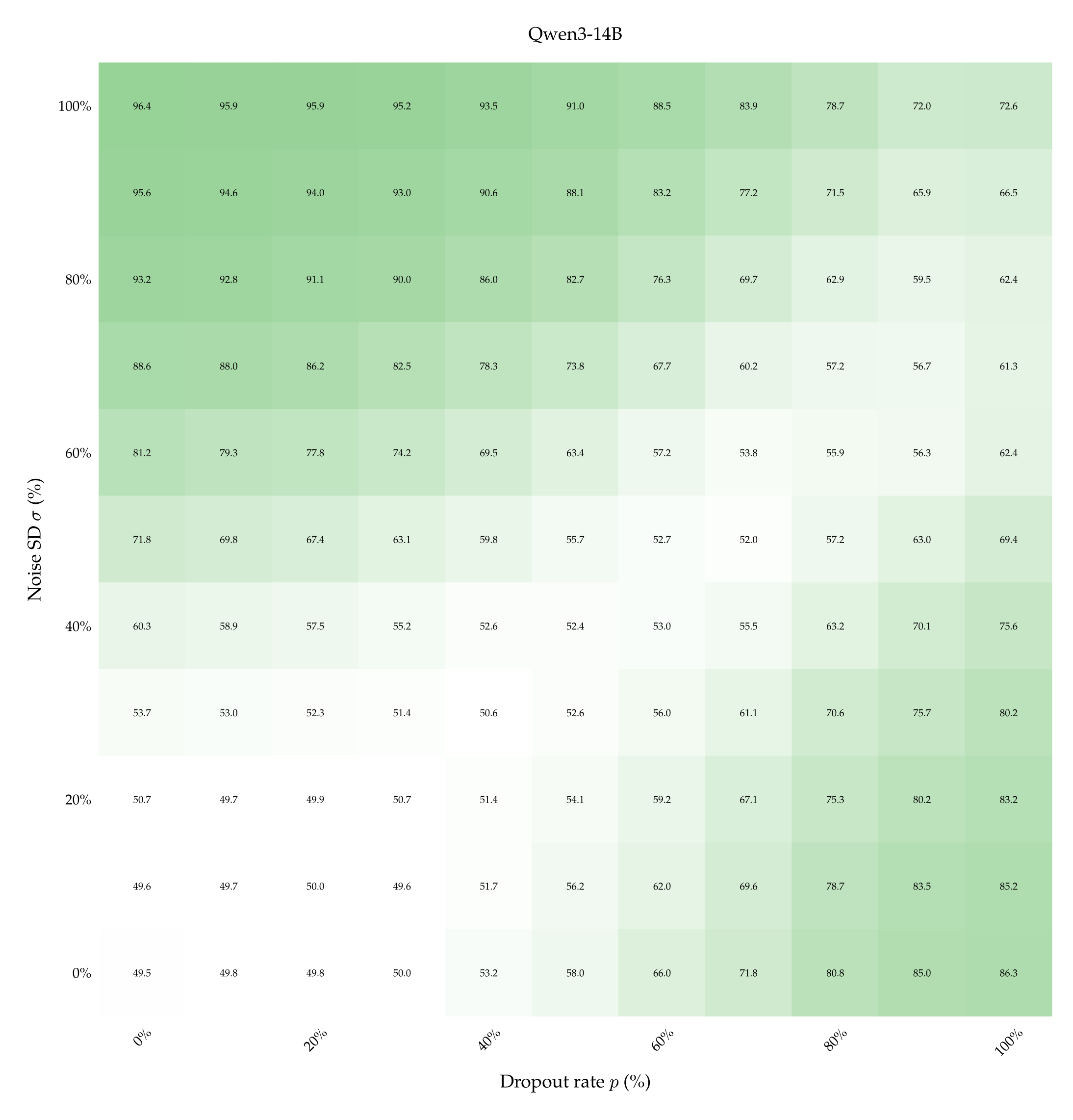
This excludes that Qwen3-32B learns only by virtue of comparing a stronger perturbation against a weaker one. This trends is shared with Qwen3-14B but not with Llama3.1-8B (which remains slightly below chance in entire matrix) nor with Olmo3.1-32B (which shows rising accuracy only as dropout rate increases)—see Appendix A.10. We deduce that for certain models only 1 example pair may not be enough to learn properly, suggesting the need to look at the learning dynamics as the number of examples increases.

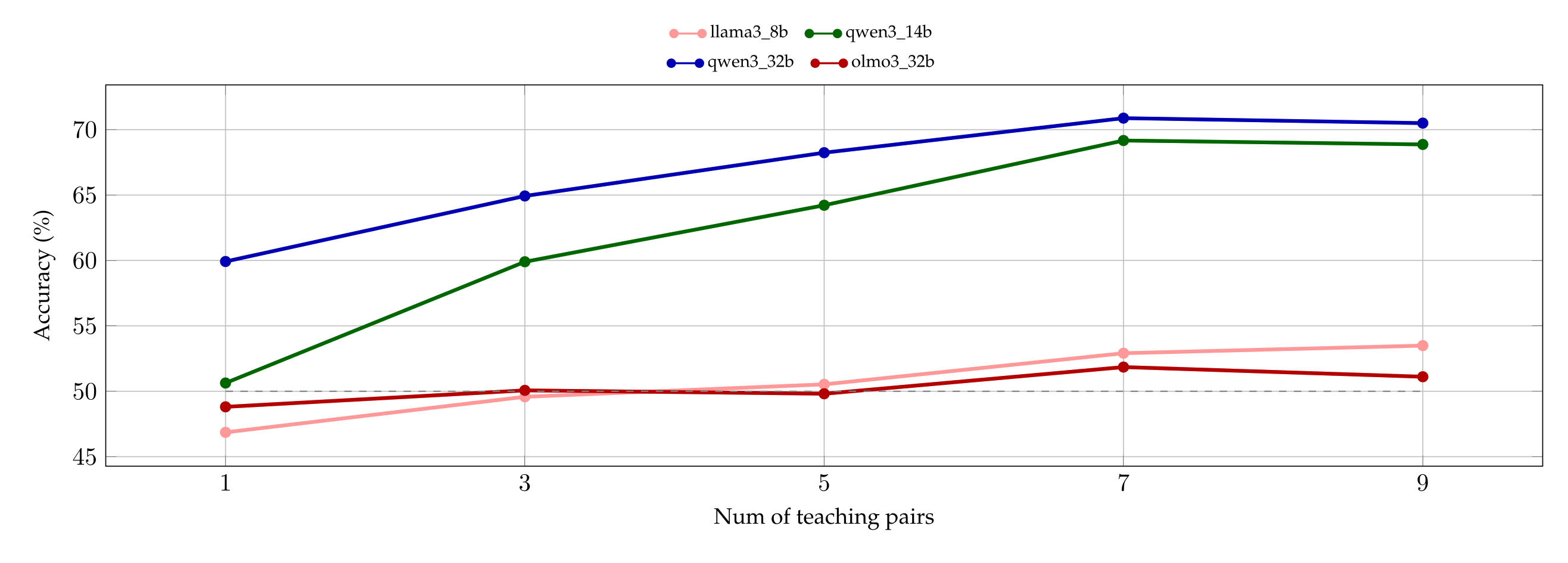
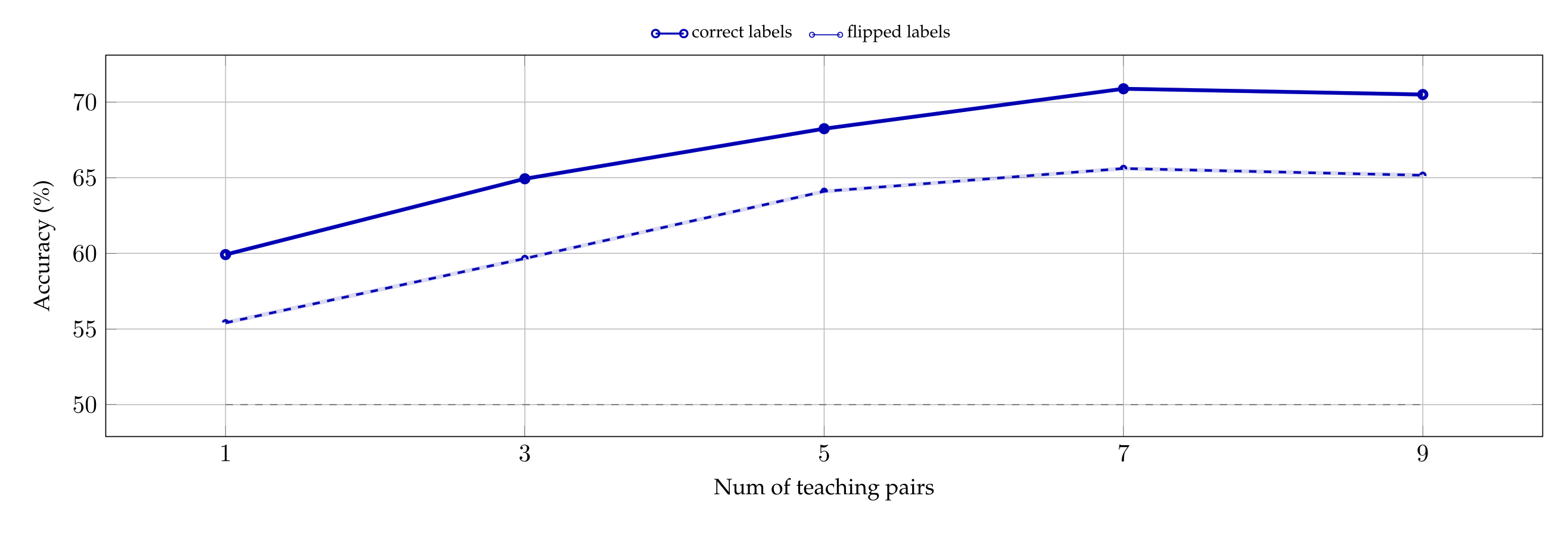
The overall effect of learning on all models, as a function of number of demonstrations. The right-hand side of Figure 5 shows the average accuracy of every model in function of the number of example pairs. For instance, the data-point corresponding to \(k = 1\) and \(M =\) Qwen3-32B (blue curve) represents the average of all the accuracies depicted in the heatmap on the left-hand side of Figure 5.
Consistently with the previous experiments, Qwen3-32B proves to be the best performing model, reaching an average accuracy above 70% when exposed to 9 in-context pairs. Qwen3-14B immediately follows its bigger version: despite starting with a chance-accuracy, it performs similarly to the 32B when it is shown 7 or 9 examples. Llama3.1-8B and Olmo3.1-32B too have accuracy that improves with the number of training examples, although the improvement is much more modest.
A closer reading of the results reveals that this less impressive behavior is partially explained by a misinterpretation of the signal. While the average accuracy of Olmo3.1-32B is just above chance, this does not mean that it fails to learn for all settings of perturbation magnitudes: its heatmaps (cf. Appendix A.10) show that accuracies reach up to 75% (when dropout is high and noise is low), or as low as 25% (when noise is high and dropout is low), meaning that it learns the wrong concept, attaching the presence of perturbation to the word “dropout“. Fully understanding this effect and testing its limits remains an interesting avenue of future investigation.
6.2. Controls

We have now seen that, at least to some extent, the difference between dropout and noise can be learned in-context. But should we (a) understand this learning as sharpening the model’s latent understanding of the difference dropout and Gaussian noise, that’s already present? Or is it better understood as (b) a new signal whose meaning really has nothing to do with what the model already knows about these two perturbations? To the extent that a model \(M\) learns to separate dropout from noise even when dropout is mislabeled as noise and noise is mislabeled as dropout, we should adopt interpretation (b): the signal is unrelated to the models’ semantic understanding of the concepts. We now test this possibility.
This task of identifying perturbations with the incorrect labels can be thought of as a kind of Stroop test [Stroop, 1935]8 for prior understanding of dropout and noise that would clash with the provided misinformation.
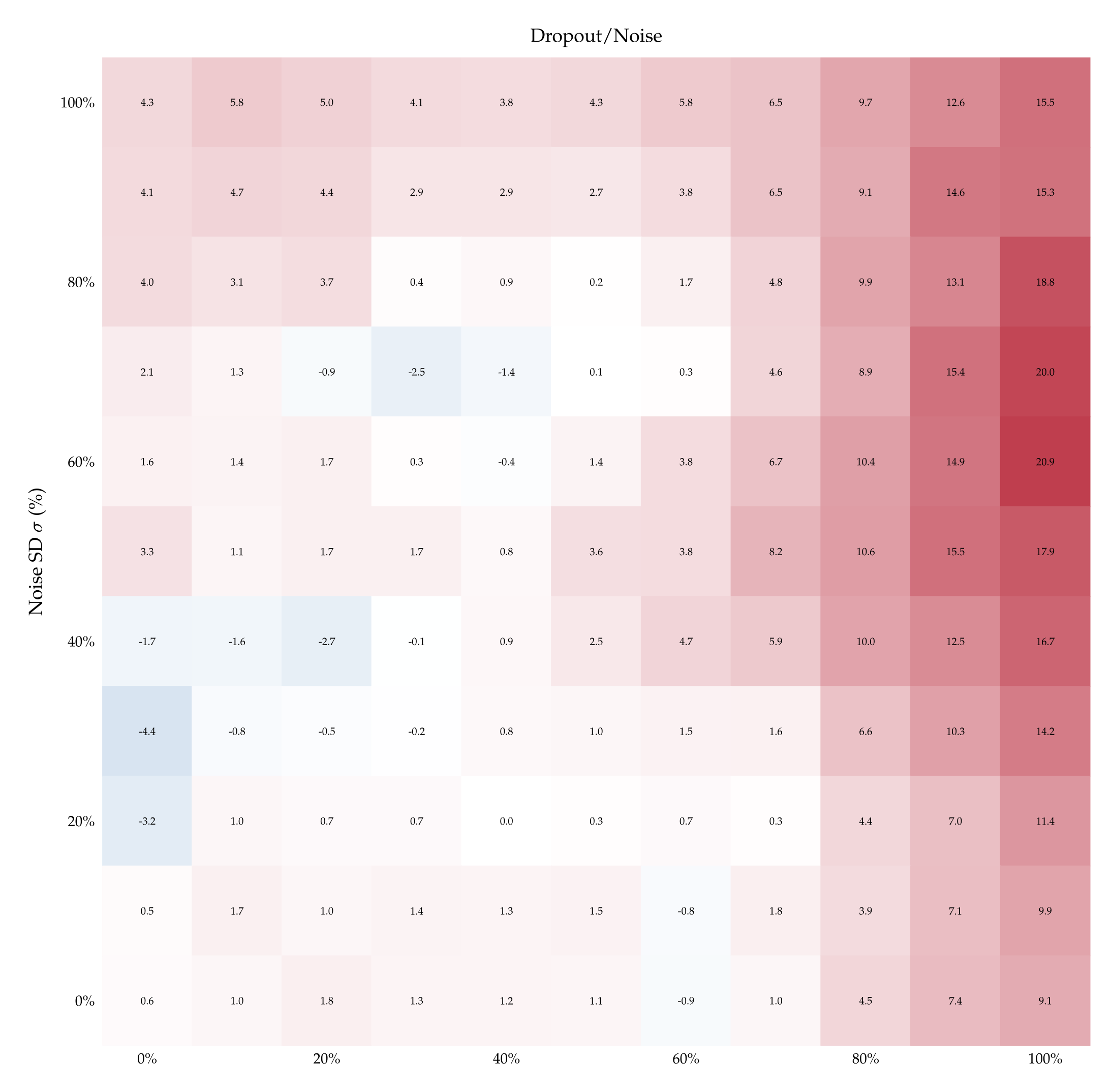
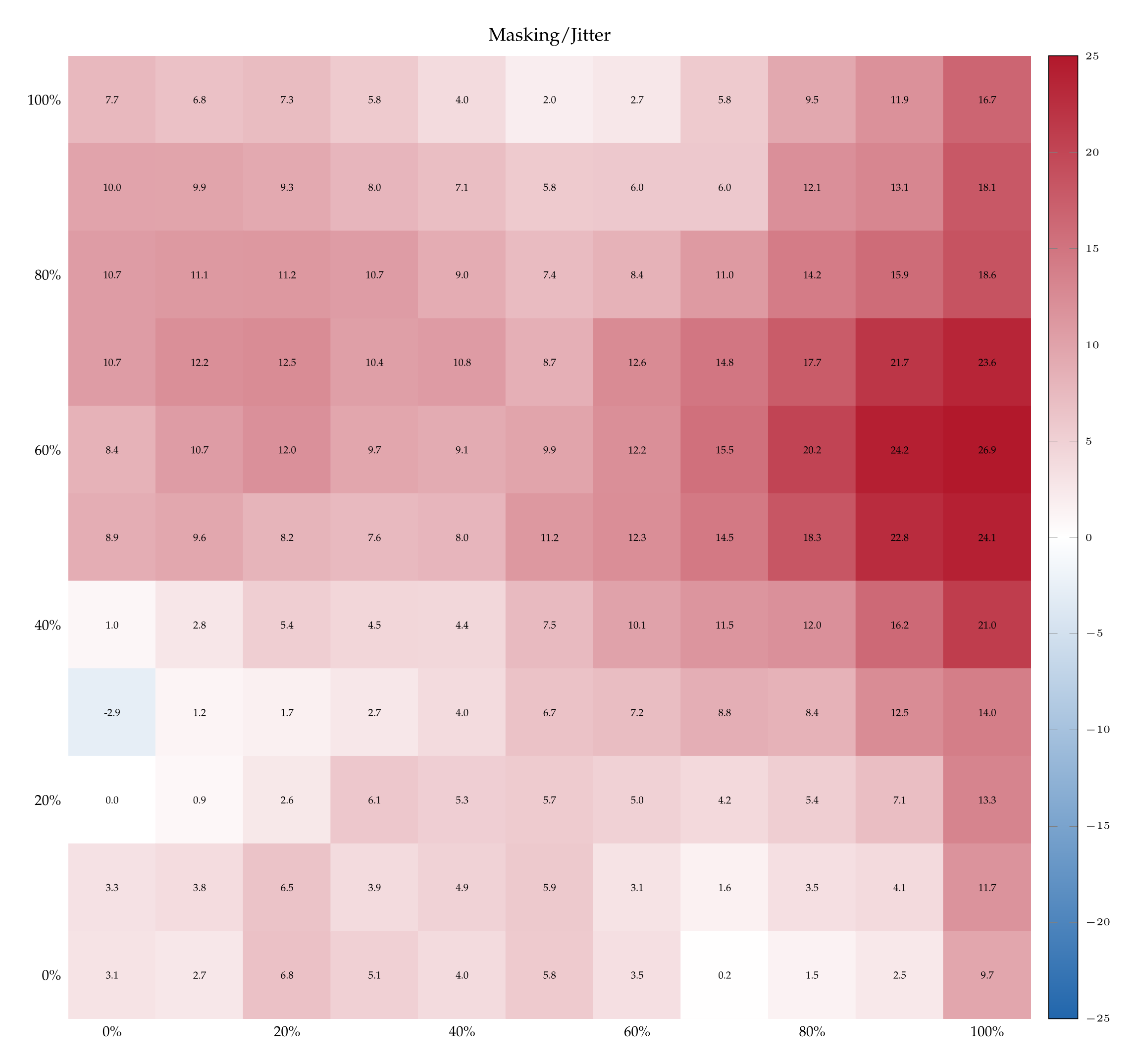
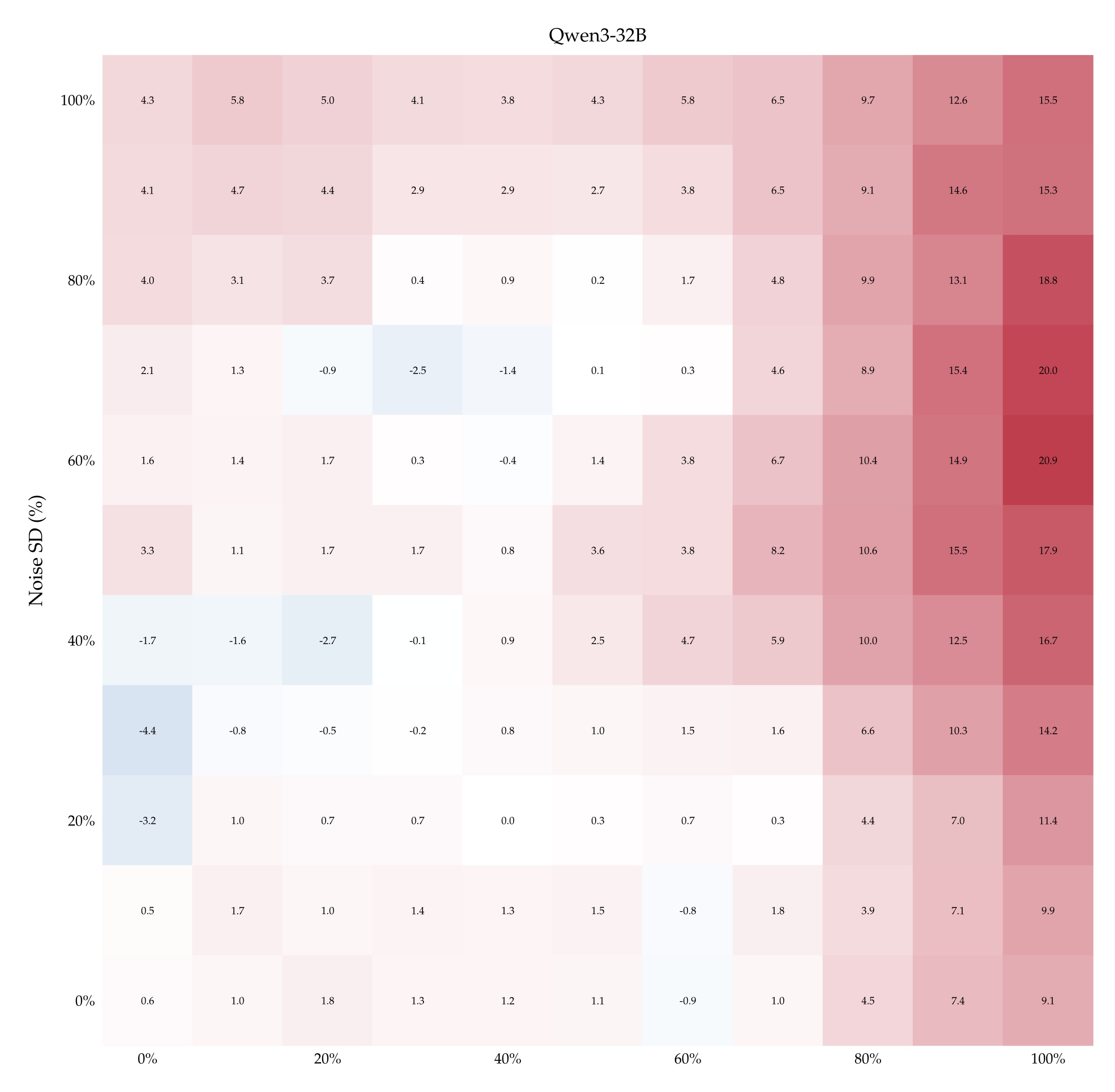
The top-left quadrant of Figure 6 depicts the difference in accuracy \( \delta_{\langle p; \sigma \rangle} \) obtained by supervising Qwen3-32B with 1 example pair of un-flipped vs flipped labels, for every pair \( \langle p; \sigma \rangle \). The fact that \( \delta_{\langle p; \sigma \rangle} > 0 \) almost everywhere indicates that the model learns better with the correct labels, suggesting a prior over them—and thus corroborating the findings of §5.1. This positive difference persists as the number of teaching examples increases and there remains a significant gap even after performance plateaus; see the right panel of Figure 21 in Appendix A.11.
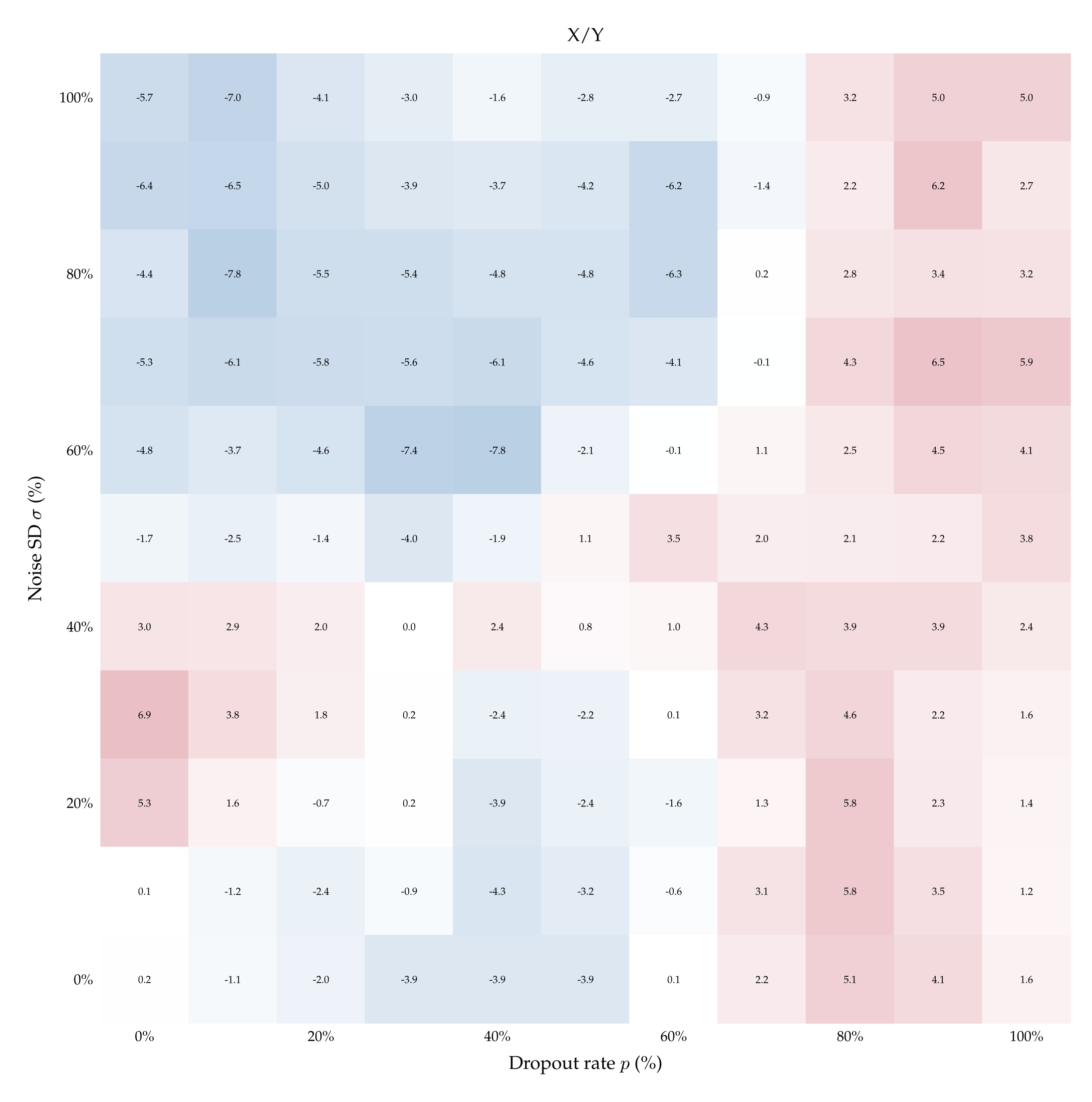
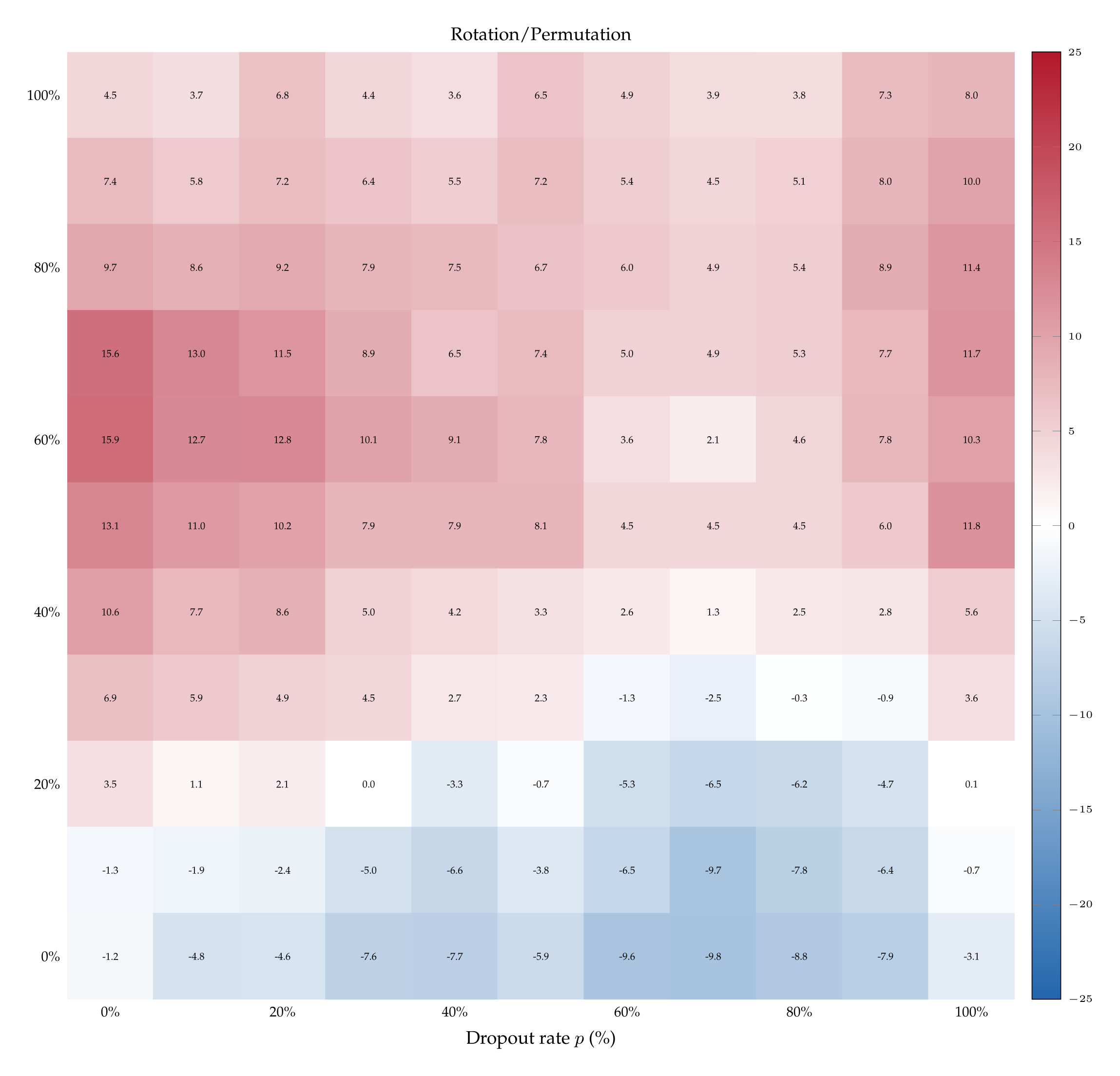
Finally, to establish that these results are not merely a coincidence about where tokens “noise“ and “dropout“ happen to lie in embedding space, we run one final suite of control experiments. We teach models to distinguish dropout from noise by naming the perturbations with control labels (e.g., ⟨X;Y⟩) and repeat the experiment with such aliases flipped (e.g., ⟨Y;X⟩). Figure 6 plots the differences in such accuracies for Qwen3- 32B (for the other models see Appendix A.12). When the teaching pairs are ⟨Masking; Jitter⟩ (synonyms of dropout and noise) and its inverse, the difference \( \delta_{\langle p; \sigma \rangle} \) is positive for almost all ⟨p; σ⟩, echoing the findings of §5.1, Figure 4. By contrast, \( \delta_{\langle p; \sigma \rangle} \) is centered around 0 almost always under neutral teaching pairs such as ⟨X;Y⟩ and ⟨Y;X⟩. Finally, under most of the labels we tested, such as ⟨Rotation; Permutation⟩, the difference \( \delta_{\langle p; \sigma \rangle} \) is significantly greater than 0 when dropout is low and noise is high, and significantly lower than 0 when dropout is high and noise is low. This indicates that Qwen3-32B learns better when the stronger perturbation—whether dropout or noise—is labeled as “rotation”. This finding is itself interesting, as it suggests that semantics carry baggage even when models need to identify a perturbation.
7. Conclusion
We showed that language models can detect and localize dropout and Gaussian noise in their activations (§4.1). Furthermore, when asked (zero-shot) to identify which perturbation they underwent (§5), Qwen3-32B performed better as the magnitude of the perturbations increased. Other models, such as Olmo3.1-32B, did not. Notwithstanding the difficulty of such a task, all the models also learned to distinguish dropout from noise when supervised with in-context examples (§6.1, A.10). In this setting, Qwen3-32B seemed to again reveal a prior for the correct teaching-labels (§6.2). We remark that the perturbations we employed are stochastic and not aligned with semantically meaningful vectors: that models can distinguish them suggests they can access and verbalize a wider signal from their activations than previously established.
Future work. Our results open a number of questions. For starters, where does this signal come from? That is, how does semantic understanding of the concepts of dropout and Gaussian noise, instilled by training, end up aligned with the models’ (first) direct “experience” of having these perturbations applied to their activations? To answer this question, it may be useful to first collect more observations. What happens if we allow the models to first generate reasoning tokens? What about other interventions, such as adding uniform noise in \( [0, 1] \) or applying quantization? We are eager to further explore the potential to connect in-context demonstrations with models’ internals.
A key question is whether the ability to recognize dropout and noise is more pronounced for models that have undergone a training stage that actually involves each of these perturbations. Observe that there is a direct incentive for a such a model to behave differently during training: if the expected answer differs from the one the model believes is best, then at inference it should give the latter. By contrast, failing to give the expected answer during training would result in a damaging update. Therefore, beyond handling issues arising from “evaluation awareness” [Bengio et al., 2026, p. 10], ensuring that a model cannot distinguish training from inference would be one further necessary step to establish trust in the assessment of a model’s behavior.
Acknowledgments
The authors are grateful for early comments and feedback to: Philippe Beaudoin, Dmitri Carpov, Raffaello Fornasiere, Josh Engels, GaÅNel Gendron, Joumana Ghosn, Pietro Greiner, Moksh Jain, Zachary Kenton, Varsha Kishore, Victoria Krakovna, Matt MacDermott, Vincent Mai, Nikolay Malkin, Ian McKenzie, Adam Oberman, Jonathan Richens, Roberta Rocca, Marc-Antoine Rondeau, Charbel-RaphaÅNel Segerie, Iulian Serban, Winnie Street.
References
Ebtesam Almazrouei, Hamza Alobeidli, Abdulaziz Alshamsi, Alessandro Cappelli, Ruxandra Cojocaru, Mérouane Debbah, Étienne Goffinet, Daniel Hesslow, Julien Launay, Quentin Malartic, Daniele Mazzotta, Badreddine Noune, Baptiste Pannier, and Guilherme Penedo. The falcon series of open language models, 2023. URL https://arxiv.org/abs/2311.16867.
Yoshua Bengio, Stephen Clare, Carina Prunkl, Maksym Andriushchenko, Ben Bucknall, Malcolm Murray, Rishi Bommasani, Stephen Casper, Tom Davidson, Raymond Douglas, et al. International ai safety report 2026. arXiv preprint arXiv:2602.21012, 2026.
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
Alexander Camuto, Matthew Willetts, Umut Simsekli, Stephen J Roberts, and Chris C Holmes. Explicit regularisation in gaussian noise injections. In H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin, editors, Advances in Neural Information Processing Systems, volume 33, pages 16603–16614. Curran Associates, Inc., 2020. URL https://proceedings.neurips.cc/paper_files/paper/2020/file/c16a5320fa475530d9583c34fd356ef5-Paper.pdf.
Iulia M Comsa and Murray Shanahan. Does it make sense to speak of introspection in large language models? arXiv preprint arXiv:2506.05068, 2025.
Mostafa Elhoushi, Akshat Shrivastava, Diana Liskovich, Basil Hosmer, BramWasti, Liangzhen Lai, Anas Mahmoud, Bilge Acun, Saurabh Agarwal, Ahmed Roman, et al. Layerskip: Enabling early exit inference and self-speculative decoding. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12622–12642, 2024.
Angela Fan, Edouard Grave, and Armand Joulin. Reducing transformer depth on demand with structured dropout, 2019. URL https://arxiv.org/abs/1909.11556.
Ely Hahami, Lavik Jain, and Ishaan Sinha. Feeling the strength but not the source: Partial introspection in llms. arXiv preprint arXiv:2512.12411, 2025.
Geoffrey E. Hinton, Nitish Srivastava, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. Improving neural networks by preventing co-adaptation of feature detectors. CoRR, abs/1207.0580, 2012. URL http://arxiv.org/abs/1207.0580.
Harvey Lederman and Kyle Mahowald. Dissociating direct access from inference in ai introspection. arXiv preprint arXiv:2603.05414, 2026.
Bonan Li, Yinhan Hu, Xuecheng Nie, Congying Han, Xiangjian Jiang, Tiande Guo, and Luoqi Liu. Dropkey for vision transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 22700–22709, June 2023.
Jack Lindsey. Emergent introspective awareness in large language models. https://transformer-circuits.pub/2025/introspection/index.html, 2025. Anthropic, Transformer Circuits thread, accessed 2026-03-27.
Houjun Liu, John Bauer, and Christopher D. Manning. Drop dropout on single-epoch language model pretraining, 2025a. URL https://arxiv.org/abs/2505.24788.
Litian Liu, Reza Pourreza, Sunny Panchal, Apratim Bhattacharyya, Yubing Jian, Yao Qin, and Roland Memisevic. Enhancing hallucination detection through noise injection. arXiv preprint arXiv:2502.03799, 2025b.
Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. Pointer sentinel mixture models. arXiv preprint arXiv:1609.07843, 2016.
Nina Panickssery, Nick Gabrieli, Julian Schulz, Meg Tong, Evan Hubinger, and Alexander Matt Turner. Steering llama 2 via contrastive activation addition, 2024. URL https://arxiv.org/abs/2312.06681.
Theia Pearson-Vogel, Martin Vanek, Raymond Douglas, and Jan Kulveit. Latent introspection: Models can detect prior concept injections. arXiv preprint arXiv:2602.20031, 2026a.
Theia Pearson-Vogel, Martin Vanek, Raymond Douglas, and Jan Kulveit. Latent introspection: Models can detect prior concept injections, 2026b. URL https://arxiv.org/abs/2602.20031.
J Ridley Stroop. Studies of interference in serial verbal reactions. Journal of experimental psychology, 18(6):643,1935.
Cameron Tice, Philipp Alexander Kreer, Nathan Helm-Burger, Prithviraj Singh Shahani, Fedor Ryzhenkov, Fabien Roger, Clement Neo, Jacob Haimes, Felix HofstÅNatter, and Teun van derWeij. Noise injection reveals hidden capabilities of sandbagging language models, 2025. URL https://arxiv.org/abs/2412.01784.
Alexander Matt Turner, Lisa Thiergart, Gavin Leech, David Udell, Juan J Vazquez, Ulisse Mini, and Monte MacDiarmid. Steering language models with activation engineering. arXiv preprint arXiv:2308.10248, 2023.
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Ł ukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017. URL https://proceedings.neurips.cc/paper_files/paper/2020/file/c16a5320fa475530d9583c34fd356ef5-Paper.pdf.
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report. arXiv preprint arXiv:2505.09388, 2025.
Lin Zehui, Pengfei Liu, Luyao Huang, Junkun Chen, Xipeng Qiu, and Xuanjing Huang. Dropattention: A regularization method for fully-connected self-attention networks, 2019. URL https://arxiv.org/abs/1907.11065.
Wangchunshu Zhou, Tao Ge, Ke Xu, Furu Wei, and Ming Zhou. Scheduled drophead: A regularization method for transformer models, 2020. URL https://arxiv.org/abs/2004.13342.
Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, et al. Representation engineering: A top-down approach to ai transparency. arXiv preprint arXiv:2310.01405, 2023.
A - Appendix
A.1 Models
The exact model nouns we experimented with are: Llama-3.1-8B-Instruct, Olmo-3.1-32B-Instruct, Qwen3-14B, or Qwen3-32B. We also experimented with Gemma-3-1b-it, Olmo-3-7B-Instruct, Qwen3-4B-Instruct-2507, Qwen3-8B, and Qwen3-30B-A3B-Instruct-2507, but did not find enough variance in the results to justify allocating compute resources for all of them.
A.2 Prompts
Each experiment relies on a pool of 20 prompts sampled uniformly. We report an example of a prompt for each experiment. Refer to Figure 7 for Localization (§4) and Figure 8 for the corresponding control (§4.2), to Figure 9 for Zero-Shot Classification (§5), and to Figure 10 for Few-Shots Classification (§6)




A.3. Dropout in transformers
Applying dropout at the output of the Attention and of the MLP components before the residual connection is closely related to one of the three ways dropout is applied in Vaswani et al. [2017, Sec 5.4]. The only difference is that we mask the activations after softmax\((QK^\top / \sqrt{d_k})V \) , as opposed to applying it before multiplying by \(V\) as done originally. Our approach makes an easier comparison with how Gaussian noise is usually added, and is simpler to implement as a hook within the Hugging Face library. Nonetheless, we experimented with several ways to apply dropout, including adding all the other components from Vaswani et al. [2017], without noticing significant variance within our results.
A.4. Localization: accuracy over multiple sentence-lengths
We report the accuracy of each model as the target sentence varies in token-length. The token-count is relative to the tokenizer of Qwen3-14B (or, equivalently, Qwen3-32B, as they have the same tokenizer, cf. Yang et al. [2025, page 3]). The tokenizers of the other models employ less tokens. Detecting perturbations is harder with fewer tokens, as visible in the following plots; therefore, we opted to overestimate the number of tokens per sentence so as to provide the non-Qwen models with a marginally harder task. Standard errors are below 1.58% and hence difficult to visualize.
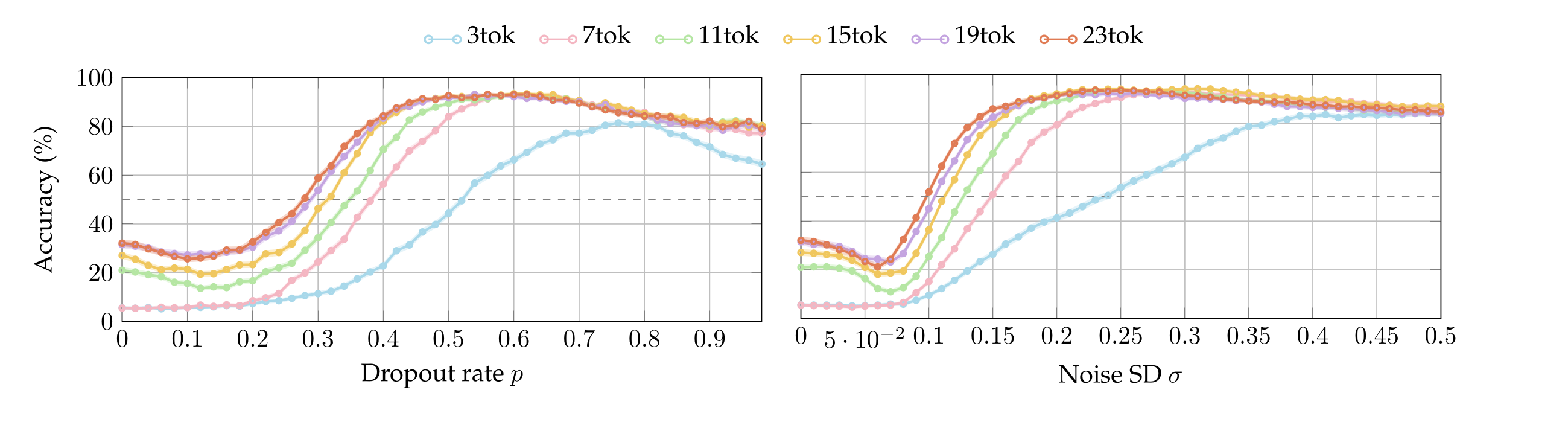
A.5. Localization: Olmo3.1-32B accuracy between labels
In the localization experiments, the accuracy Olmo3.1-32B starts below chance for small values of dropout rate and noise SD. Interestingly, this is because, at the question “Which sentence had a perturbation applied?” the model answers neither despite the prefill The answer is: . Therefore, the plots below show the model’s accuracy when taking into account the logits of the tokens ‘ A’ and ‘ B’, ignoring the \( \arg \max \) token neither.
A.6 Localization: controls
High accuracy in the localization experiment (§4) could be due to models disproportionally choosing a perturbed sentence irrespective of the semantic content of the question. To control for this, we present models with two sentences, each about exactly one topic. We perturb exactly one of the two sentences, and then ask the model which question was about a certain topic. The pair of topics are: animals / cities, gardening/ vehicles, ocean / mountain, sports / music, and weather / technology. Examples of the sentences are below.

A.7. Zero-shot classification: control labels
The accuracy of Qwen3-32B in the zero-shot classification experiment (§5) could be due to the possibility that applying dropout (resp. adding noise) steers the activations in a way that systematically favors saying “dropout” (resp. noise), irrespective of the semantic content of our question. If this is the case, we would expect to see similar trends if, while still applying dropout or noise, the question asked would be different, such as “Which perturbation did we apply, X or Y?”. To control for this, we test Qwen3-32B with 50 pairs of control labels. For instance, we ask the model (paraphrasing): “Did we apply Rotation or Permutation?”. In these controls we then keep track of the number of times the model says Rotation (resp. Permutation) when the underlying perturbation is dropout (resp./ noise). Most of the control labels are semantically unrelated to dropout and noise, but we also use pseudo-synonyms of dropout and noise such as Masking and Jitter, and their permutations. See the full list of controls in Table 2.
Because Llama3.1-8B Qwen3-14B, and Olmo3.1-32B did not display accurate behavior at the zero-shot task, we tested only a few control labels: X/Y, Foo/Bar, Masking/Jitter,Rotation/Permutation, Scaling/Translation, Vanilla/Chocolate.
A.8 Zero-shot classification: Qwen3-14B and Llama3.1-8B.
Accuracy of Llama3.1-8B and Qwen3-14B at the zero-shot classification task (§5), as a function of dropout rate and noise SD. The corresponding plots for Qwen3-32B and Olmo3.1-32B are in the main text.
A.9. Zero-shot classification: entropy
Accuracy in the zero-shot classification experiment (§5) might be polluted by the fact that applying dropout (resp. noise) increases the probability mass of every token in a systematic way. Therefore, we report the entropy of the whole distribution of tokens, so as to maintain a global view on what applying dropout (resp./adding noise) causes.
A.10 Few-shot classification: heatmaps of all models
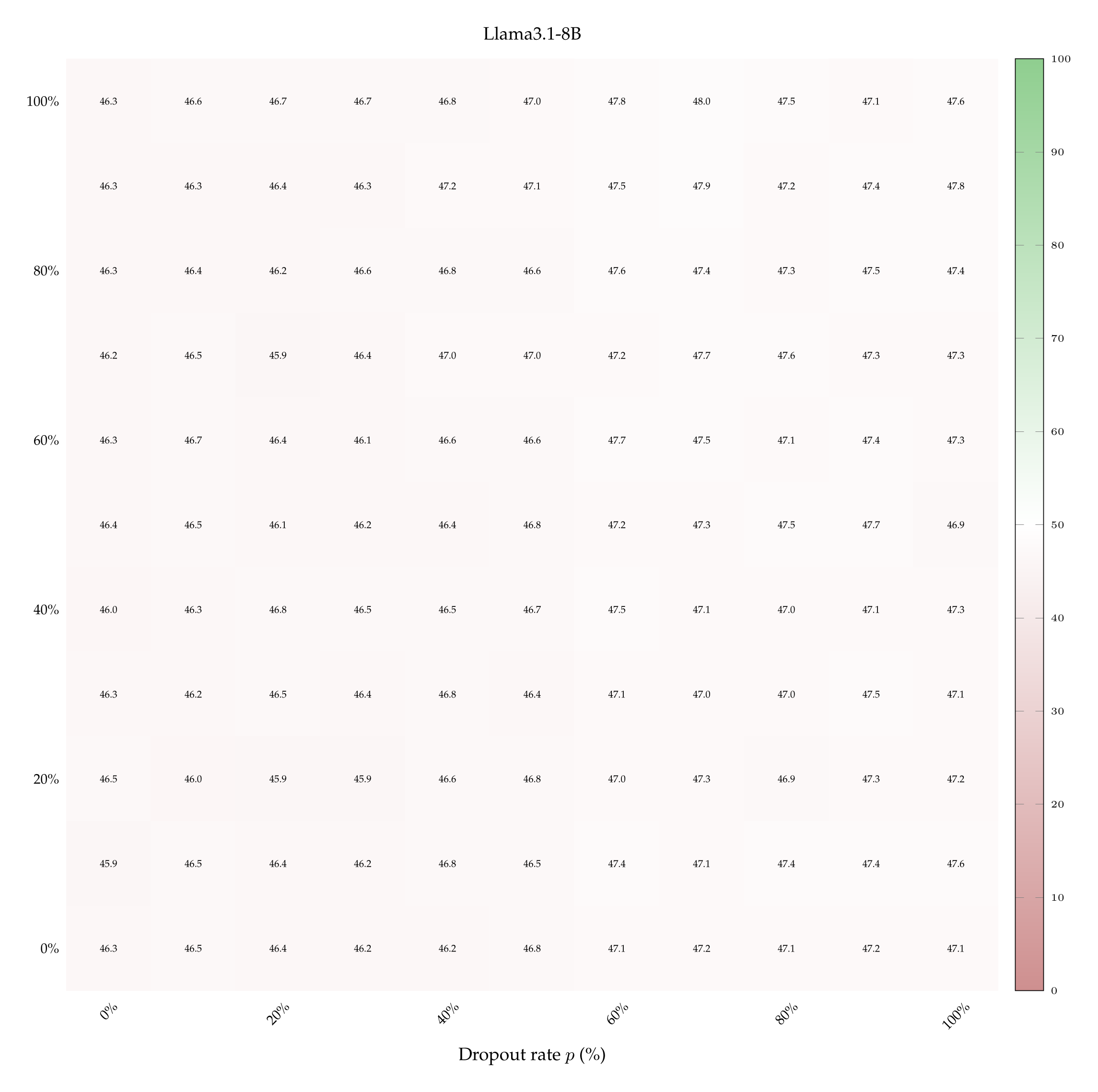
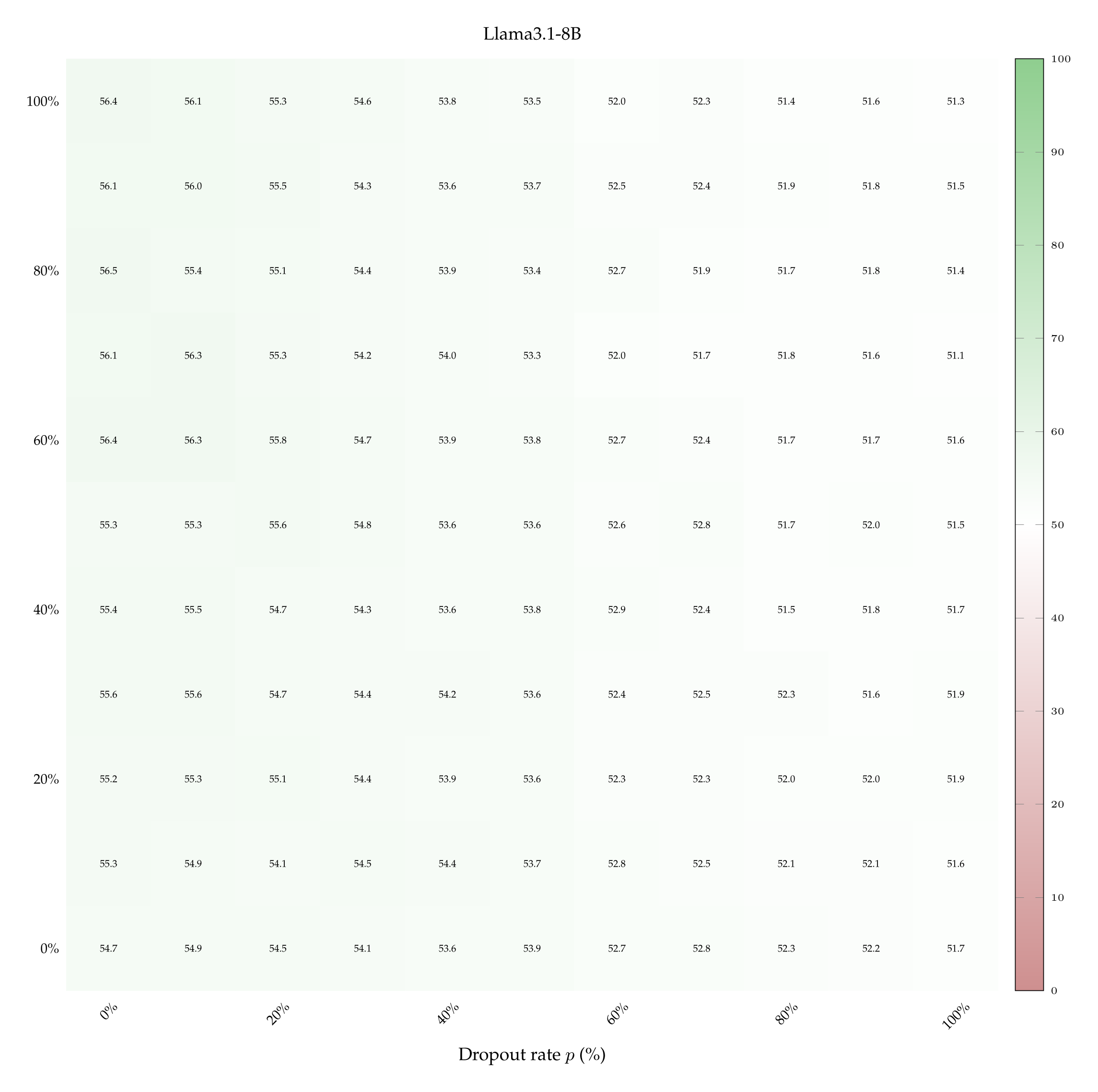
We report the heatmaps displaying accuracy at the few-shot classification task, for the Llama3.1-8B, Qwen3-14B and Olmo3.1-32B models. In particular, we show the accuracy of each model as a function of dropout rate, noise SD, when the model sees 1 or 9 in-context example pairs.


A.11 Few-shot classification: flipped labels
The left-hand side of Figure 21 plots accuracy of Qwen3-32B when taught with one in-context example and flipped labels. That is, we ask the model to distinguish dropout from noise, yet “dropout” is named “noise” and vice versa. As the right-hand side of the same picture shows, the model still learns to succeed at the (inverted) task, yet with lower accuracy than with the correct labels, suggesting a prior for them.

A.12 Few-shot classification: delta heatmaps
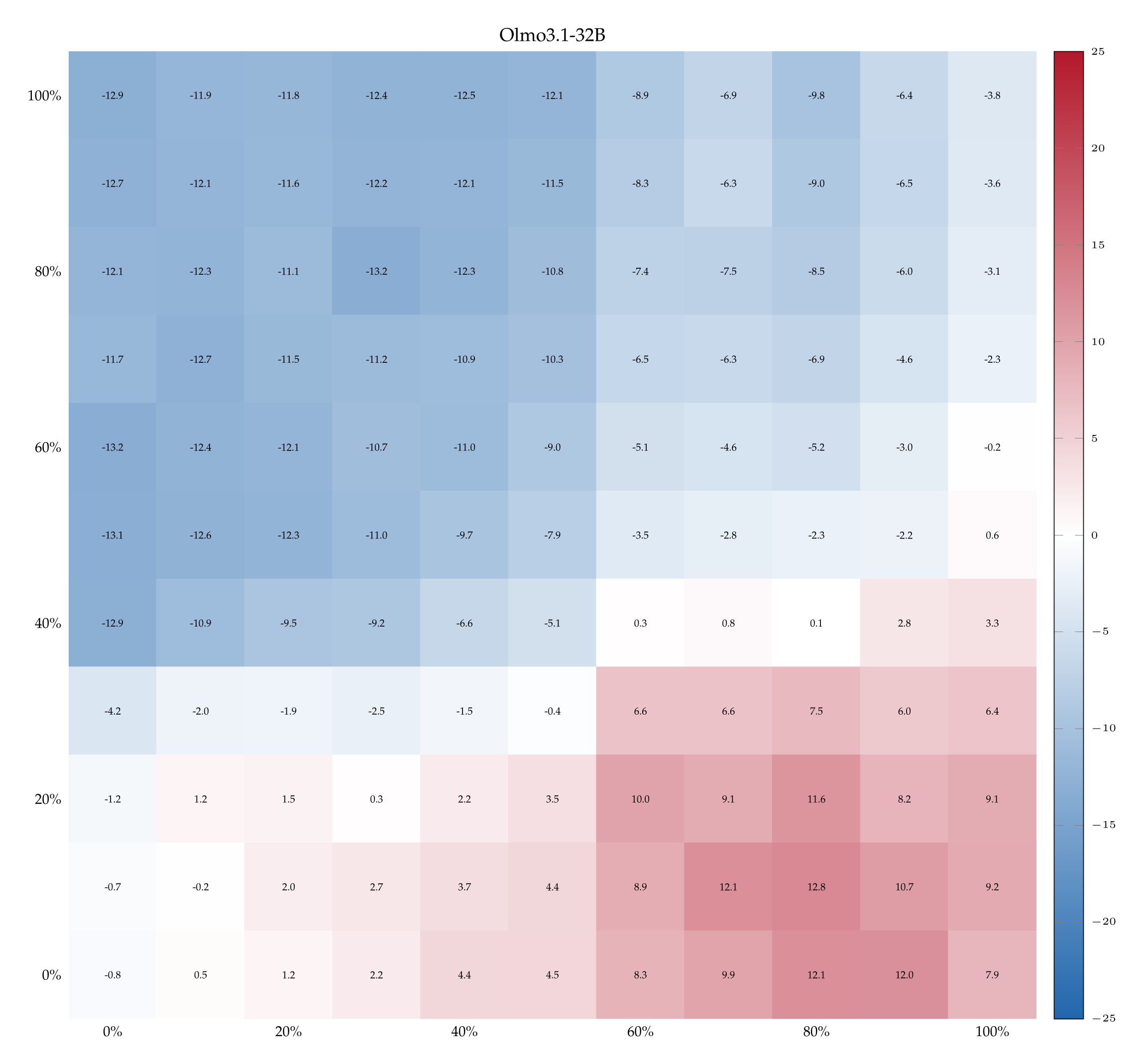
We report the heatmaps with the delta accuracy between the correct labels minus the swapped labels for the dropout / noise experiment for Llama3.1-8B, Qwen3-14B and Olmo3.1-32B.

- This project page provides an overview of the results. The code and data are available at this https URL and this https URL.
- For the exact model names see Appendix A.1. We also experimented with Gemma-3-1b-it, Olmo-3-7B-Instruct, Qwen3-4B-Instruct-2507, Qwen3-8B, and Qwen3-30B-A3B-Instruct-2507, but did not find enough variance in the results to justify allocating compute resources for all of them.
- To exclude that our results might be polluted because \(M\) memorized WikiText-103, we repeated the experiments by sampling the target sentences from two other pools: one synthetic dataset generated by Claude Opus 4.1, and one synthetic dataset generator built by us. In either case, we have not recorded appreciable difference in the results.
- We note that applying dropout at the output of the Attention and of the MLP components before the residual connection is closely related to one of the three ways dropout is applied in Vaswani et al. [2017, Sec 5.4], see Appendix A.3 for details.
- For some models, we re-ran this experiment so as to provide more granularity on the 𝓍-axis where the accuracy shifted too abruptly. For Olmo3.1-32B (which sometimes answers “neither”) we obtained \( p_{\min} \) by comparing the relative accuracy of the correct answer to its alternative.
- The value \( \sigma_{\max} \) associated with Olmo3.1-32B does not fall in the range \( [0.0, 0.5] \). We therefore test Olmo3.1-32B on more values, see the results in Appendix A.6.
- Observe that the case with zero examples coincides with the zero-shot experiment presented in §5, modulo a minimal rephrasing of the first sentence in the prompt.
- In Stroop’s classical psychological experiment, participants are given a list of color words printed in different colors (e.g., blue, white, orange), and asked to list the corresponding colors rather than reading words (e.g., green, red, blue). It is uniformly observed that literate participants are much slower and make more mistakes when the labels are wrong.